通用源码阅读指导书
书籍简介
《通用源码阅读指导书——MyBatis源码详解》是一本以MyBatis源码为材料,详细介绍源码阅读相关方法和技巧的源码阅读指导书籍。
本书以MyBatis源码中的包为单位,详细和透彻地介绍每个类的源码,包括其背景知识、组织方式、逻辑结构、实现细节。在本书的讲解中,不漏过每一个类,不跳过每一个难点,做到深浅一致。在阅读MyBatis源码的过程中,本书使用了运行初探、模块归类、合理猜测、类比阅读、网格阅读等许多源码阅读方法,并对这些源码阅读方法进行了进一步的总结整理。
本书适合架构师、程序员提升自己的源码阅读能力、系统架构能力、软件开发能力,也有助于产品经理、测试人员、运维人员等从业者了解软件架构细节。
书籍购买地址: 京东

书籍购买地址: 京东
书籍目录
- 前言
- 【模块 一】背景介绍
- 1 源码阅读
- 2 MyBatis概述
- 2.1 背景介绍
- 2.2 快速上手
- 2.2.1 MyBatis包的引入
- 2.2.2 MyBatis的简单配置
- 2.2.3 基于MyBatis的数据库操作
- 2.3 MyBatis的核心功能分析
- 3 MyBatis运行初探
- 3.1 初始化阶段追踪
- 3.1.1 静态代码块的执行
- 3.1.2 获取InputStream
- 3.1.3 配置信息读取
- 3.1.4 总结
- 3.2 数据读写阶段追踪
- 3.2.1 获得SqlSession
- 3.2.2 映射接口文件与映射文件的绑定
- 3.2.3 映射接口的代理
- 3.2.4 SQL语句的查找
- 3.2.5 查询结果缓存
- 3.2.6 数据库查询
- 3.2.7 处理结果集
- 3.2.8 总结
- 3.1 初始化阶段追踪
- 4 MyBatis源码结构概述
- 4.1 包结构
- 4.2 分组结构
- 【模块 二】基础功能包源码阅读
- 5 exceptions包
- 5.1 背景知识
- 5.1.1 Java的异常
- 5.1.2 序列化与反序列化
- 5.2 Exception类
- 5.3 ExceptionFactory类
- 5.1 背景知识
- 6 reflection包
- 6.1 背景知识
- 6.1.1 装饰器模式
- 6.1.2 反射
- 6.1.3 Type接口及其子类
- 6.2 对象工厂子包
- 6.3 执行器子包
- 6.4 属性子包
- 6.5 对象包装器子包
- 6.6 反射核心类
- 6.7 反射包装类
- 6.8 异常拆包工具
- 6.9 参数名解析器
- 6.10 泛型解析器
- 6.1 背景知识
- 7 annotations包与lang包
- 7.1 背景知识
- 7.1.1 Java注解详解
- 7.2 Param注解分析
- 7.1 背景知识
- 8 type包
- 8.1 背景知识
- 8.1.1 模板模式
- 8.2 类型处理器
- 8.2.1 类型处理器基类与实现类
- 8.2.2 TypeReference类
- 8.3 类型注册表
- 8.1 背景知识
- 9 io包
- 9.1 背景知识
- 9.1.1 单例模式
- 9.1.2 代理模式
- 9.1.3 静态代理
- 9.1.4 VFS
- 9.2 VFS实现
- 9.2.1 DefaultVFS
- 9.2.2 JBoss6VFS
- 9.3 类文件的加载
- 9.4 ResolverUtil类
- 9.1 背景知识
- 10 logging包
- 11 parsing包
- 11.1 背景知识
- 11.1.1 XML文件
- 11.1.2 XPath
- 11.2 XML解析
- 11.3 文档解析中的变量替换
- 11.1 背景知识
- 【模块 三】配置解析包源码阅读
- 12 配置解析概述
- 13 binding包
- 13.1 数据库操作的接入
- 13.1.1 数据库操作的方法化
- 13.1.2 数据库操作方法的接入
- 13.2 抽象方法与数据库操作节点的关联
- 13.3 数据库操作接入总结
- 13.3.1 初始化阶段
- 13.3.2 数据读写阶段
- 13.4 MyBatis与Spring、Spring Boot的整合
- 13.1 数据库操作的接入
- 14 builder包
- 14.1 背景知识
- 14.1.1 建造者模式
- 14.2 建造者基类与工具类
- 14.3 SqlSourceBuilder与StaticSqlSource
- 14.4 CacheRefResolver和ResultMapResolver
- 14.4.1 CacheRefResolver类
- 14.4.2 ResultMapResolver类
- 14.5 ParameterExpression类
- 14.6 XML文件解析
- 14.6.1 XML文件的声明解析
- 14.6.2 配置文件解析
- 14.6.3 数据库操作语句解析
- 14.6.4 Statement解析
- 14.6.5 引用解析
- 14.7 注解映射的解析
- 14.7.1 注解映射的使用
- 14.7.2 注解映射解析的触发
- 14.7.3 直接注解映射的解析
- 14.7.4 间接注解映射的解析
- 15 mapping包
- 15.1 SQL语句处理功能
- 15.1.1 MappedStatement类
- 15.1.2 SqlSource类
- 15.1.3 BoundSql
- 15.2 输出结果处理功能
- 15.2.1 ResultMap
- 15.2.2 ResultMapping
- 15.2.3 Discriminator
- 15.3 输入参数处理功能
- 15.4 多数据库种类处理功能
- 15.5 其他功能类
- 15.1 SQL语句处理功能
- 16 scripting包
- 16.1 背景知识
- 16.1.1 OGNL
- 16.2 语言驱动接口及语言驱动注册表
- 16.3 SQL节点树的组建
- 16.4 SQL节点树的解析
- 16.4.1 OGNL辅助类
- 16.4.2 表达式求值器
- 16.4.3 动态上下文
- 16.4.4 SQL节点及其解析
- 16.5 再论SqlSource
- 16.5.1 SqlSource的生成
- 16.5.2 DynamicSqlSource的转化
- 16.5.3 RawSqlSource的转化
- 16.5.4 SqlSource接口的实现类总结
- 16.1 背景知识
- 17 datasource包
- 17.1 背景知识
- 17.1.1 java.sql包和javax.sql包
- 17.1.2 DriverManager
- 17.1.3 DataSource
- 17.1.4 Connection
- 17.1.5 Statement
- 17.2 数据源工厂接口
- 17.3 JNDI数据源工厂
- 17.4 非池化数据源及工厂
- 17.4.1 非池化数据源工厂
- 17.4.2 非池化数据源
- 17.5 池化数据源
- 17.5.1 池化数据源类的属性
- 17.5.2 池化连接的给出与收回
- 17.5.3 池化连接
- 17.6 论数据源工厂
- 17.1 背景知识
- 【模块 四】核心操作包源码阅读
- 18 jdbc包
- 18.1 AbstractSQL类与SQL类
- 18.1.1 SafeAppendable内部类
- 18.1.2 SQLStatement内部类
- 18.1.3 AbstractSQL类
- 18.1.4 SQL类
- 18.2 SqlRunner
- 18.3 ScriptRunner
- 18.4 jdbc包的独立性
- 18.1 AbstractSQL类与SQL类
- 19 cache包
- 19.1 背景知识
- 19.1.1 Java对象的引用级别
- 19.1.2 ReferenceQueue
- 19.2 cache包结构与Cache接口
- 19.3 缓存键
- 19.3.1 缓存键的原理
- 19.3.2 缓存键的生成
- 19.4 缓存的实现类
- 19.5 缓存装饰器
- 19.5.1 同步装饰器
- 19.5.2 日志装饰器
- 19.5.3 清理装饰器
- 19.5.4 阻塞装饰器
- 19.5.5 定时清理装饰器
- 19.5.6 序列化装饰器
- 19.6 缓存的组建
- 19.7 事务缓存
- 19.8 MyBatis缓存机制
- 19.8.1 一级缓存
- 19.8.2 二级缓存
- 19.8.3 两级缓存机制
- 19.1 背景知识
- 20 transaction包
- 20.1 背景知识
- 20.1.1 事务概述
- 20.2 事务接口及工厂
- 20.3 JDBC事务
- 20.4 容器事务
- 20.1 背景知识
- 21 cursor包
- 21.1 背景知识
- 21.1.1 Iterable接口与Iterator接口
- 21.2 MyBatis中游标的使用
- 21.3 游标接口
- 21.4 默认游标
- 21.4.1 CursorStatus内部类
- 21.4.2 ObjectWrapperResultHandler内部类
- 21.4.3 CursorIterator内部类
- 21.4.4 DefaultCursor外部类
- 21.1 背景知识
- 22 executor包
- 22.1 背景知识
- 22.1.1 基于cglib的动态代理
- 22.1.2 javassist框架的使用
- 22.1.3 序列化与反序列化中的方法
- 22.1.4 ThreadLocal
- 22.1.5 存储过程
- 22.1.6 Statement及其子接口
- 22.2 主键自增功能
- 22.2.1 主键自增的配置与生效
- 22.2.2 Jdbc3KeyGenerator
- 22.2.3 SelectKeyGenerator
- 22.3 懒加载功能
- 22.3.1 懒加载功能的使用
- 22.3.2 懒加载功能的实现
- 22.3.3 懒加载功能对序列化和反序列化的支持
- 22.4 语句处理功能
- 22.4.1 MyBatis对多语句类型的支持
- 22.4.2 MyBatis的语句处理功能
- 22.5 参数处理功能
- 22.6 结果处理功能
- 22.7 结果集处理功能
- 22.7.1 MyBatis中多结果集的处理
- 22.7.2 结果集封装类
- 22.7.3 结果集处理器
- 22.8 执行器
- 22.8.1 执行器接口
- 22.8.2 执行器基类与实现类
- 22.9 错误上下文
- 22.1 背景知识
- 23 session包
- 23.1 SqlSession及其相关类
- 23.1.1 SqlSession的生成链
- 23.1.2 DefaultSqlSession类
- 23.1.3 SqlSessionManager类
- 23.2 Configuration类
- 23.3 其他类
- 23.1 SqlSession及其相关类
- 24 plugin包
- 24.1 背景知识
- 24.1.1 责任链模式
- 24.2 MyBatis插件开发
- 24.3 MyBatis拦截器平台
- 24.4 MyBatis拦截器链与拦截点
- 24.1 背景知识
- 【模块 五】总结与展望
- 25 源码阅读总结
- 25.1 前期准备
- 25.1.1 工具准备
- 25.1.2 项目选择
- 25.1.3 项目使用
- 25.2 项目初探
- 25.3 源码阅读
- 25.3.1 模块分析
- 25.3.2 模块归类
- 25.3.3 自底向上
- 25.3.4 合理猜测
- 25.3.5 类比阅读
- 25.3.6 善于汇总
- 25.3.7 网格阅读
- 25.1 前期准备
- 26 优秀开源项目推荐
- 26.1 Guava
- 26.2 Tomcat
- 26.3 Redis
- 26.4 Dubbo
- 26.5 React
书籍内容
本页面提供《通用源码阅读指导书》中部分章节的试读。
试读章节未经校审,以出版的书籍内容为准。
书籍购买地址: 京东
前言
有一段时间,我觉着我非要阅读开源项目的源码不可。
那时,我已经在公司负责设计和开发了许多系统。如果连大学时带领大家开发和维护学校网站也算上的话,我已经进行软件开发整整十个年头了。在这十个年头里,我对自己设计和开发的系统都很有信心。但却有一个疑惑一直在我心头萦绕:我不知道,我的架构和世界最优良架构之间的差距到底有多大。
阅读开源项目的源码能给我答案。
许多优秀的开源项目历经数千开发者的数万次提交,被数亿用户使用。这些项目从可扩展性、可靠性、可用性等各个角度考量,都是十分优良的。通过阅读这些项目的源码能让我找到自己在软件设计和开发上的不足。
于是我开始了我的源码阅读计划。
在阅读源码的过程中,我看过不少资料。但很多资料对于源码中简单的部分讲解的细致入微;而对复杂的部分则避而不谈或含糊其辞。 在阅读源码的过程中,我也走过了不少弯路。经常在一个难点中挣扎很久不得前进。
当然,阅读源码也让我收获颇丰。它不仅让我知道了自己的设计与优良设计之间的差距,还让我学到了许多的架构技巧、编程知识。在源码阅读的过程我也总结出了许多的经验和方法。因此,我决定写这本书,将这些经验和方法分享出来,指引许多和我一样前行在源码阅读道路上的人。
源码阅读首先要选定相应的源码作为材料。从项目的成熟度、涉及面、应用广度、项目规模等多方面考虑,本书最终选中MyBatis的源码。因此,本书将以阅读MyBatis源码为例,介绍源码阅读的经验和方法。
在本书的写作中,我努力做到详尽而不罗嗦。本书以包为单位,对MyBatis源码中的300多个类都进行了介绍。在这个过程中,对于简单或重复的类一笔带过,但对于越复杂的类则越是逐方法、逐行地分析。力求让大家读的顺、读的懂、有收获。
本书一共分为了五个模块,每个模块的主要内容如下。
背景介绍模块:
第1章介绍了源码阅读的意义和方法。
第2章对MyBatis的背景和快速上手方法进行了介绍。这一章的内容是简单但重要的。对于任何一个软件,其背景对应于软件的“设计需求”,其使用对应于软件的“主要功能”。把握了一个软件设计需求和主要功能对于阅读软件的源码很有帮助。
第3章中使用断点调试方法对MyBatis的执行过程进行了追踪。该章节的内容有助于我们了解整个MyBatis的内部框架。
第4章对MyBatis的源码结构进行了介绍,并根据源码包的功能对包进行了分类。
基础功能包源码阅读模块:
在这一模块中,我们对5个基础功能包中的源码进行了阅读。基础功能包相对独立,与MyBatis的核心逻辑耦合小,比较适合作为我们源码阅读的切入点。在阅读这些源码时,我们也会逐步介绍一些阅读源码时常用的方法技巧。
第5章介绍了exceptions包的源码。我们可以通过该包了解MyBatis的整个异常体系。
第6章介绍了reflection包的源码。该包基于反射提供了创建对象、修改对象属性、调用对象方法等功能。这些功能在MyBatis的参数处理、结果处理等环节都发挥了重要的作用。
第7章介绍了annotations包与lang包的源码。这两个包中全是注解类。我们将通过对Java注解的学习详细了解每个注解类的含义。最后,我们还通过源码分析了注解类如何在MyBatis的运行中发挥作用。
第8章介绍了type包的源码。通过这一章我们将了解MyBatis如何组织和实现类型处理器,以完成对各种类型数据的处理。
第9章介绍了io包的源码。通过该包我们将了解到MyBatis如何完成外部类的筛选和载入。
第10章介绍了logging包的源码。logging包不仅为MyBatis提供了日志记录功能,还提供了获取和记录JDBC中日志的功能。通过这一章节,我们将了解这些功能的实现细节。
第11章介绍了parsing包的源码。通过这一章,我们将了解MyBatis如何完成XML文件的解析。
配置解析包源码阅读模块:
第12章介绍了配置解析相关类的分类方法。对于配置解析类相关的类可以按照类的功能将其划分为解析器类或解析实体类。
第13章介绍了binding包的源码。该包负责将SQL语句接入到映射接口中。
第14章介绍了builder包的源码。该包中的建造者基类和工具类为MyBatis基于建造者模式建造对象提供了基础。此外,该包还完成了映射文件和映射注解的解析工作。
第15章介绍了mapping包的源码。该包完成了SQL语句的处理、输入参数的处理、输出结果的处理等功能,并为MyBatis提供了多数据库支持的能力。
第16章介绍了scripting包的源码。就是在这个包中,复杂的SQL节点被逐步解析为纯粹的SQL语句。该章节将带我们详细了解这一解析过程。
第17章介绍了datasource包的源码。该包包含了MyBatis中与数据源相关的类,包括非池化数据源、池化数据源、数据源工厂等。也正是通过该包,MyBatis完成了和数据库的对接。
核心操作包源码阅读模块:
在这一模块中,我们将详细介绍MyBatis的核心操作包。
第18章介绍jdbc包的源码。该包仅使用6个类便为MyBatis提供了运行SQL语句和脚本的能力。
第19章介绍了cache包的源码。该包向我们展示了MyBatis如何使用装饰器模式为用户提供丰富的、可配置的缓存。并且该章节还从功能维度出发详细介绍了MyBatis的两级缓存机制。
第20章介绍了transaction包的源码。该包为MyBatis提供了内部和外部的事务支持。
第21章介绍了cursor包的源码。通过该包,MyBatis能将查询结果封装为游标形式返回。
第22章介绍了executor包的源码。executor包是MyBatis中最为重要也是最复杂的包。在这一章中,我们以子包为单位分别介绍了MyBatis的主键自增功能、懒加载功能、语句处理功能、参数处理功能、结果处理功能、结果集处理功能。然后在此基础上对MyBatis中执行器的源码进行了阅读。最后,我们阅读了MyBatis中错误上下文的源码,了解MyBatis如何及时地保留错误发生时的现场环境。
第23章介绍了session包的源码。session包是一个对外接口包,是用户在使用MyBatis时接触最多的包。
第24章介绍了plugin包的源码。在该章节中我们编写了一个插件,然后通过源码详细了解了MyBatis插件的实现原理以及MyBatis插件平台的架构。
总结与展望模块:
第25章对阅读MyBatis源码过程中的技巧方法进行了总结。
第26章从项目的成熟度、涉及面、应用广度、规模等角度综合考量为大家推荐了一些优秀的开源项目。学习完本书后,大家可以从这些项目中挑选一些进行源码阅读。
源码阅读毕竟是一个对知识广度和深度都有较高要求的工作。为了大家能够顺利地阅读MyBatis的源码,我们会在很多章节之前介绍该章节源码涉及的基础知识。先掌握这些基础知识后再阅读相关源码则会轻松很多。
受篇幅所限,书中只能给出部分MyBatis源码。我们将完整的带中文注释的MyBatis源码整理成了开源项目供大家下载、参考。该项目的地址为:https://github.com/yeecode/MyBatisCN。
为了大家能更轻松地理解和掌握一些相对复杂的知识点,我们还准备了许多示例项目。该示例项目也开源供大家下载,地址为:https://github.com/yeecode/MyBatisDemo。
受限于我的水平和时间,书中难免会有疏漏之处。您可以通过我的个人主页与我取得联系并与我交流。在那里也能看到我的最新项目。我的个人主页地址是:http://yeecode.top。
通过阅读本书,您将详细了解MyBatis中每一个类的结构、原理、细节。但要注意,这只是我们阅读本书的额外收获。掌握源码阅读的方法和技巧,并将这些方法技巧应用到其他项目的源码阅读工作、系统设计工作、软件开发工作中,这才是阅读本书的最终目的。
源码阅读是一个过程艰苦而结果可观的工作。每一个潜心阅读源码的开发者都值的尊敬,也希望本书能够在您源码阅读的过程中为您提供一些帮助,让您多一些收获。
加油!奋斗路上的你和我。
【模块 一】背景介绍
在本模块中,我们将对源码阅读的背景和方法进行初步的介绍,同时还会对本书的结构进行一些说明。
我们也会在本模块中简要介绍MyBatis的使用方法和运行原理,并在此基础上对MyBatis的源码结构进行初步的分析,为后续章节的源码阅读打好基础。
1 源码阅读
1.1 源码阅读的意义
计算机技术和通信技术的蓬勃发展催生了一批又一批的软件开发者。对于软件开发者而言,学校的教科书、网上的培训视频都是非常好的入门资料。正是这些入门资料,帮我们打下了软件开发的基础。
信息时代的飞速发展也带来了许许多多的新概念,物联网、区块链、人工智能、云计算……层出不穷的新概念为我们描绘出了一幅幅壮美的蓝图。介绍这些概念的书籍也如雨后春笋般不断涌现。
然而,在这基础和蓝图之间却有着巨大的知识断层:我们很容易找到用来夯实基础的入门书籍,也很容易找到用来阐述蓝图的分析文章,可是却少有资料来告诉我们如何从基础开始构建出蓝图中的雄伟建筑。于是,众多的开发者迷失在了基础和蓝图的知识断层中,如同一个手握铁锤的建筑工人看着摩天大楼的规划图却不知从何下手。于是有人选择了放弃,继续在增删改查中沉沦;有人选择了摸索,不断在重构改版中挣扎。
本书的目的不是帮开发者构建软件开发的基础,也不是向开发者描绘新概念的蓝图。本书是为了给开发者指引一条从基础到蓝图的前进道路,帮助开发者掌握在扎实的基础上建造蓝图中雄伟建筑的能力。
源码阅读,是去理解和分析优秀的开源代码,并从中积累和学习的过程。就如同剖析一个摩天大楼的内部构造般去分析一个优秀开源项目的组织划分、结构设计、功能实现,进而学习借鉴并最终应用到自己的项目中,提升自己的软件设计和开发能力。
源码阅读也是一个优秀软件开发者必备的能力。如今绝大多数的软件都是团队协作的结果,只有读懂别人的代码才能继续开发新的功能。甚至即使是单兵作战,也需要读懂自己所写的旧代码后才能开展新的工作。
优秀的源码是最棒的编程教材,它能将整个项目秋毫毕现地呈现给我们,使我们获得全面的提升。源码阅读能让我们:
- 透彻地理解项目的实现原理
- 接触到成熟和先进的架构方案
- 学习到可靠与巧妙的实施技巧
- 发现自身知识盲点,提升自身知识储备
因此,源码阅读是软件开发者提升自身能力极为重要的手段。
1.2 源码阅读的方法
源码阅读对于提升开发者的技术能力大有裨益,可源码阅读的过程却是极为痛苦的。
每一个优秀的工程项目都凝聚了众多开发者的缜密思维逻辑;每一个优秀的工程项目都经历了从雏形到成熟的曲折演化过程。最终,这些思维逻辑和演化过程都会投射和堆叠到源码上,使得源码变得复杂和难以理解的。因此,源码阅读的过程是一个通过源码去逆推思维逻辑和演化过程的工作。于是有人说读懂源码比编写源码更为困难,想必也是有一定道理的。
当我们阅读一份源码时,需要面对的困难通常有:
- 难以归纳的凌乱文件
- 稀奇古怪的类型组织
- 混乱不堪的逻辑跳转
- 不明其意的方法变量
- ……
可是,舒适能带来的只是原地踏步。正是梳理这些凌乱文件、理解这些类型组织、追踪这些逻辑跳转、弄清这些方法变量的痛苦过程,才是真的能让我们获得提升的过程。
源码阅读的过程中也有一些技巧,掌握这些技巧能减少源码阅读过程中的痛苦。授人以鱼不如授人以渔,本书会将源码阅读中的方法技巧总结出来,并希望大家将它们应用在其他项目的源码阅读中。我们先将一些基本的技巧介绍如下,更过的技巧将会在源码阅读的过程中不断给出。
- 调试追踪:多数情况下,当我们对某些变量的含义产生疑惑时,借助开发工具的调试功能直接查看变量值的变化是一个非常好的方法。而且该方法还能指引代码逻辑的跳转过程,对于理解源码极为有用。
- 归类总结:优秀的源码都遵循一定的设计规则,这些规则可能是项目间通用的,也可能是项目内独有的。在源码阅读的过程中将这些设计规则总结出来,将会使得源码阅读的过程越来越顺畅。
- 上下文整合:有些对象、属性、方法等仅仅通过自身很难判断其作用和实现。此时可以结合其调用的上下文,查看对象何时被引用、属性怎样被赋值、方法为何被调用,这对于了解它们的作用和实现很有帮助。
另外还有一点不得不提,那就是有一套强大的开发工具。有一套支持代码高亮、错误提示、引用跳转、断点调试等功能开发工具十分有必要。它能让我们快速定位到所调用的方法,也能让我们快速找到当前变量的引用,这些功能是进行源码阅读所必须的。在Java编程领域,强大的开发工具有IDEA、Eclipse等,大家可以根据自己的喜好选用。
1.3 开源软件
开源软件(open source software),即开放源代码软件。这一类软件具有极强的开放性,其源代码被公开出来供大众获取、学习、修改,甚至重新分发。也正因为其开放性,一些开源软件吸引了众多开发者参与其中,而这些开发者中不乏领域内的顶尖大牛。
以linux源代码为例,截至目前它经历过21000多名开发者的840000多次提交。这充分说明它是众多开发者智慧的结晶,也从侧面说明了该项目代码的严谨与优雅。
所以说优秀的开源软件是进行源码阅读的绝佳材料。
Github平台是全球最为知名的开源软件库,众多优秀的开源软件就是在Github平台上协作开发的。我们可以到Github平台寻找自己领域内的优秀开源软件开展源码阅读工作。图1-1便展示了Java领域的一些优秀开源项目。
- apache/dubbo:一个高性能的远程过程调用框架
- netty/netty:事件驱动的异步网络应用框架
- spring-projects/spring-boot:一套简单易用的Spring框架
- alibaba/fastjson:一套快速的的JSON解析、生成组件
- apache/kafka:一套实时数据流处理平台
- mybatis/mybatis-3:一套强大的对象关系映射工具
除了上述项目外,Github上还有众多优秀的开源软件供给大家使用、学习、甚至是参与开发。
1.4 MyBatis源码
经过不断的筛选,本书最终选择了开源软件MyBatis作为源码阅读的材料。这主要基于以下几个方面的考虑:
- MyBatis项目悠久且成熟,且有着极广的应用范围,目前有十余万开源项目引用它。
- MyBatis包括数据库操作、对象关系映射、配置文件解析、缓存处理等众多功能,涉及的知识面十分广泛。
- MyBatis源码的代码量比较合适,如果代码量太多则一本书难以细致地讲完,而如果代码量太少则不能充分暴露出源码阅读过程中可能遇到的问题。
因为MyBatis是我们源码阅读的材料,所以学习完本书后,我们不仅会学到源码阅读的方法技巧,还会对MyBatis的实现原理、代码结构、设计技巧等了如指掌。最终,我们会成为一个MyBatis的精通者,这算是学习本书的额外收获。因此,你也可以单纯地将本书作为一本MyBatis源码解析书来看待。
本书所使用的MyBatis版本为最新的稳定版3.5.2,其开源项目地址为:https://github.com/mybatis/mybatis-3/releases/tag/mybatis-3.5.2。
不过我们建议你在阅读本书时参照上述代码的中文注释版进行,其开源项目地址为:https://github.com/yeecode/MyBatisCN。
该版本在3.5.2版本的基础上增加了中文注释。由于书本字数所限,很多书本上没有展示的代码及注释也能在该版本中找到。因此这是阅读本书时非常必要的辅助资料。
1.5 本书结构
在这一节我们将对本书的结构进行简要的介绍。同时考虑到本书会涉及MyBatis的相关文件和大量的源码,我们也会在这一章节对源码分析中涉及到的术语进行规范。
1.5.1 背景知识
如果要说什么是源码阅读中最重要的因素,那应该是基础知识。
如果不了解开源项目中的设计模式,则很难理清楚源码的结构;如果不清楚开源项目中的编程知识,则很难弄明白逻辑的走向。因此,掌握好开源项目中用到的相关基础知识非常重要。
为了使大家能更好地理解源码,我们会在每个章节开始将章节所述源码中涉及的知识介绍给大家。这些知识包括但不限于:
- 设计模式
- Java基础与进阶知识
- 项目使用到的外部工具包
- 项目依赖到的外部类
大家可以根据自己的知识储备对这些背景知识进行学习后再进行章节内源码的阅读。
为了大家能够更快地消化和吸收相关的知识,我们还准备了大量的示例,并将这些示例汇总成了一个开源项目MyBatisDemo,其开源地址为:https://github.com/yeecode/MyBatisDemo。
1.5.2 文件的指代
使用MyBatis时,会涉及到三类文件。我们对这三类文件分别进行简要的介绍,在本书后面的叙述中,将使用这些名称来指代相应的文件。
1.5.2.1 配置文件
MyBatis的配置文件为一个XML文件,通常被命名为mybatis-config.xml。该XML文件的根节点为configuration,根节点内可以包含的一级节点及其含义如下所示:
- properties: 属性信息,相当于MyBatis的全局变量。
- settings:设置信息,通过这里对MyBatis的功能进行调整。
- typeAliases:类型别名,在这里我们可以为类型设置一些简短的名字。
- typeHandlers:类型处理器,在这里我们可以为不同的类型设置相应的处理器。
- objectFactory:对象工厂,在这里可以指定MyBatis创建新对象时使用的工厂。
- objectWrapperFactory:对象包装器工厂,在这里可以指定MyBatis使用的对象包装器工厂。
- reflectorFactory:反射器工厂,在这里可以设置MyBatis的反射器的工厂。
- plugins:插件,在这里可以为MyBatis配置差价,从而修改或者扩展MyBatis的行为。
- environments:环境,这里可以配置MyBatis运行的环境信息,例如数据源信息等。
- databaseIdProvider:数据库编号,在这里可以为不同的数据库配置不同的编号,这样可以对不同类型的数据库设置不同的数据库操作语句。
- mappers:映射文件,在这里可以配置映射文件或者映射接口文件的地址。
同时要注意,配置文件中的一级节点是有顺序要求的,必须按照上面列举的顺序出现。在使用中可以根据实际需要选择相应的节点依次写入配置文件。
代码1-1展示了一个简单的配置文件示例。
【代码 1-1】
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<typeAliases>
<package name="com.github.yeecode.mybatisdemo.model"/>
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://127.0.0.1:3306/yeecode?serverTimezone=UTC"/>
<property name="username" value="root"/>
<property name="password" value="yeecode"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="com/github/yeecode/mybatisDemo/UserMapper.xml"/>
</mappers>
</configuration>
1.5.2.2 映射文件
映射文件也是一个XML文件,用来完成Java方法与SQL语句的映射、Java对象与SQL参数的映射、SQL查询结果与Java对象的映射等。通常,在一个项目中可以有多个映射文件。
映射文件的根节点为mapper,在mapper节点下可以包含的节点和相应的含义如下所示:
- cache: 缓存,通过它可以对当前命名空间进行缓存配置。
- cache-ref: 缓存引用,通过它可以引用其他命名空间的缓存作为当前命名空间的缓存。
- resultMap: 结果映射,通过它来配置如何将SQL查询结果映射为对象。
- parameterMap: 参数映射,通过它来配置如何将参数对象映射为SQL参数。该节点已被废弃,建议直接使用内联参数。
- sql: SQL语句片段,通过它来设置可以被复用的语句片段。
- insert: 插入语句。
- update: 更新语句。
- delete: 删除语句。
- select: 查询语句。
代码1-2即给出了一个简单的映射文件示例。
【代码 1-2】
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.github.yeecode.mybatisdemo.dao.UserMapper">
<select id="queryUserBySchoolName" resultType="User">
SELECT * FROM `user` WHERE schoolName = #{schoolName}
</select>
</mapper>
在映射文件中,insert、update、delete、select节点最为常见,我们把这类节点统称为数据库操作节点,而将节点的内容是一个支持复杂语法的SQL语句,我们称为数据库操作语句。如图1-2所示。

1.5.2.3 映射接口文件
映射接口文件是一个Java接口文件,并且该接口不需要实现类。通常情况下,每个映射接口文件都有一个同名的映射文件与之相对应。
在映射接口文件中可以定义一些抽象方法,这些抽象方法可以分为两类:
- 第一类抽象方法与对应的映射文件中的数据库操作节点相对应。
- 第二类抽象方法通过注解声明自身的数据库操作语句。当整个接口文件中均为该类抽象方法时,则该映射接口文件可以没有对应的映射文件。
代码1-3给出了一个映射接口文件的示例。
【代码 1-3】
public interface UserMapper {
// 该抽象方法对应着映射文件中的数据库操作节点
List<User> queryUserBySchoolName(User user);
// 该抽象方法通过注解声明了自身的数据库操作语句
@Select("SELECT * FROM `user` WHERE `id` = #{id}")
User queryUserById(Integer id);
}
因为映射接口文件实际是一个Java接口,有时我们也会称其为映射接口。
1.5.3 方法的指代
1.5.3.1 方法名
在Java程序中,常常会针对于某一方法重载出多个方法,以满足不同使用情况下的使用需求。例如,代码1-4是CacheException类的一组构造方法,一共包含了四个入参不同的方法:
【代码 1-4】
// 方法一
public CacheException() {
super();
}
// 方法二
public CacheException(String message) {
super(message);
}
// 方法三
public CacheException(String message, Throwable cause) {
super(message, cause);
}
// 方法四
public CacheException(Throwable cause) {
super(cause);
}
在本书中,我们将使用CacheException来指代具有该方法名的上述四个方法。而使用CacheException()来特指方法一,使用CacheException(String, Throwable)来特指方法三。
这种方法的指代方式参考自《Java编程风格》一书。
1.5.3.2 核心方法
某些情况下,具有相同方法名的一组方法是为了便于外部调用而重载出来的,其核心实现逻辑都集中在某一个方法内,其他方法只是充当转接适配的工作。
例如,代码1-5所示的三个selectMap方法中,方法一、二中仅仅进行了默认参数的设置、转化等简单的适配操作,然后调用了方法三。方法三中则包含了核心的操作逻辑。
【代码 1-5】
// 方法一
public <K, V> Map<K, V> selectMap(String statement, String mapKey) {
return this.selectMap(statement, null, mapKey, RowBounds.DEFAULT);
}
// 方法二
public <K, V> Map<K, V> selectMap(String statement, Object parameter, String mapKey) {
return this.selectMap(statement, parameter, mapKey, RowBounds.DEFAULT);
}
// 方法三
public <K, V> Map<K, V> selectMap(String statement, Object parameter, String mapKey, RowBounds rowBounds) {
final List<? extends V> list = selectList(statement, parameter, rowBounds);
final DefaultMapResultHandler<K, V> mapResultHandler = new DefaultMapResultHandler<>(mapKey,
configuration.getObjectFactory(), configuration.getObjectWrapperFactory(), configuration.getReflectorFactory());
final DefaultResultContext<V> context = new DefaultResultContext<>();
for (V o : list) {
context.nextResultObject(o);
mapResultHandler.handleResult(context);
}
return mapResultHandler.getMappedResults();
}
在本书中,我们将方法三这样的包含核心操作逻辑的方法称为核心方法。所以,selectMap(String, Object, String, RowBounds)就是selectMap这一组方法中的核心方法。
非核心方法中的代码大多十分简单和易于理解,因此在后面的源码分析中,我们多围绕核心方法开展。
2 MyBatis概述
在展开一个项目的源码阅读之前,首先要对整个项目有着较为全面的了解。需要了解的信息包括项目的产生背景、演进过程、使用方法等,这些信息能帮助我们直观地建立出整个项目的外在轮廓。这样,在我们遇到一段代码时就能根据外在轮廓更好地揣测它在整体功能中的作用,最大限度地减少理解偏差的产生。
在本章节我们将概括性地了解MyBatis项目,包括其背景介绍、快速上手方法等,而对于一些更为细节的使用方法将会在相关部分的源码解析时介绍。
2.1 背景介绍
2.1.1 传统数据库连接
数据库是软件项目中存储持久化数据的最常用的场所,应用十分广泛。例如在网站应用中,注册用户的信息、页面展示的信息、用户提交的信息等大都是存储在数据库中的。因此与数据库进行交互是很多软件项目中非常重要的部分。
然而,软件程序与数据库交互的过程需要建立连接、拼装和执行SQL语句、转化操作结果等步骤,相对比较繁琐。代码2-1是一个从数据库中查询User列表的示例。
【代码 2-1】
// 第一步:加载驱动程序
Class.forName("com.mysql.jdbc.Driver");
// 第二步:获得数据库的连接
Connection conn = DriverManager.getConnection(url, userName, password);
// 第三步:创建语句并执行
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("SELECT * FROM `user` WHERE schoolName = \'" + userParam.getSchoolName() + "\';");
// 第四步:处理数据库操作结果
List<User> userList = new ArrayList<>();
while(resultSet.next()){
User user = new User();
user.setId(resultSet.getInt("id"));
user.setName(resultSet.getString("name"));
user.setEmail(resultSet.getString("email"));
user.setAge(resultSet.getInt("age"));
user.setSex(resultSet.getInt("sex"));
user.setSchoolName(resultSet.getString("schoolName"));
userList.add(user);
}
// 第五步:关闭连接
stmt.close();
该示例的完整代码请参见MyBatisDemo项目中的示例1
在运行示例前需要先使用MyBatisDemo项目database文件夹下的SQL脚本初始化两个数据表。这两个数据表会在MyBatisDemo项目的多个示例中用到,我们不再重复提及。
代码2-1所示的过程中,第一、二、五步的工作是相对固定的,可以通过封装函数进行统一操作。而第三、四步的操作却因为涉及的入参和出参的Java对象不同而很难将其统一起来。
不仅是在数据的查询操作中,在数据的写入、编辑操作时也会面临同样的问题。在进行数据写入和编辑操作时往往需要处理更多的输入参数,我们需要将这些参数一一拼装到SQL语句内。
随着SQL语句的不同、输入输出参数对象的不同,上述代码中第三、四步展示的操作会千变万化,我们只能针对不同对象的不同操作拼装不同的操作语句然后单独处理返回的结果。数据库写入、读取的操作是十分频繁的,这就带来了大量繁琐的工作。
ORM框架就是为了解决上述问题而产生的。
2.1.2 ORM框架
在目前主流的软件开发过程中,多使用面向对象的开发方法和基于关系型数据库的持久化方案。
面向对象是从软件工程原则(如聚合、封装)的基础上发展而来的,而关系型数据库则是从数学理论(集合代数等)的基础上发展而来的,两者并不是完全匹配的,它们中间需要信息的转化。例如,在将对象持久化到关系型数据库中时常常需要图2-1所示的转化过程。
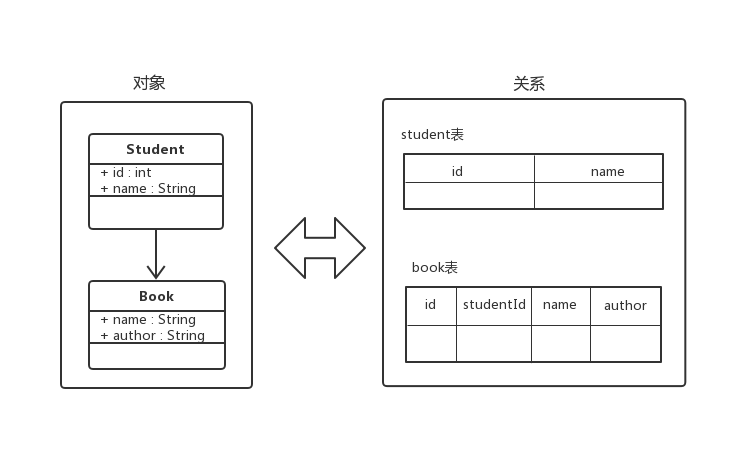
这样的转化被称为对象关系映射(英语:Object Relational Mapping,简称ORM,或O/RM,或O/R mapping)。ORM会在数据库数据的读取和写入操作过程中频繁发生,为了减少这种转化过程中的开发成本,产生了大量的ORM框架。MyBatis就是其中非常出色的一款。
2.1.3 MyBatis特点
大多数ORM框架选择将Java对象和数据表直接关联起来,用一组对应关系将两者绑定,如图2-2所示。
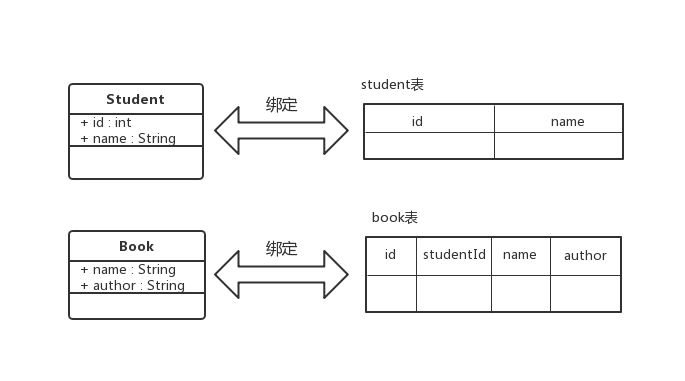
MyBatis则采取了另一种方式,它没有将Java对象和数据表直接关联起来,而是将Java方法和SQL语句关联起来。这使得MyBatis在简化了ORM操作的同时也支持了数据表的关联查询、视图的查询、存储过程的调用等操作。除此之外,MyBatis还提供了一种映射机制,将SQL语句的参数或者结果与对象关联了起来。图2-3形象地展示了MyBatis的映射机制。
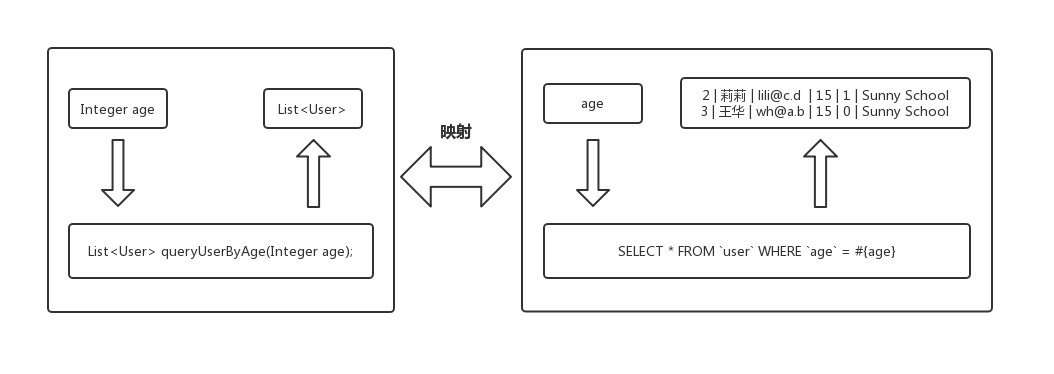
这样,使用MyBatis时,只要调用一个方法就可以执行一条复杂的SQL语句。在调用方法时可以给方法传递对象作为SQL语句的参数,而SQL语句的执行结果也会被映射成对象后返回。因此,关系型数据库被MyBatis屏蔽了,读写数据库的过程成了一个纯粹的面向对象的过程。
除了核心的映射功能外,MyBatis还提供了缓存功能、懒加载功能、主键自增功能、多数据集处理功能等,这些功能的实现原理会在后续的源码阅读中详细介绍。
10 logging包
logging包负责完成MyBatis操作中的日志记录工作。
对于大多数系统而言,日志记录是必不可少的。它能够帮助我们追踪系统的状态或者定位问题所在。MyBatis作为一个ORM框架,运行过程中可能会在配置解析、参数处理、数据查询、结果转化等各个环节中遇到错误,这时,MyBatis输出的日志便成了我们定位错误的最好资料。
10.1 背景知识
10.1.1 适配器模式
适配器模式(Adapter Pattern)是一种结构型模式,基于该模式设计的类能够在两个或者多个不兼容的类之间起到沟通桥梁的作用。
转换插头就是一个适配器的典型例子。不同的转换插头能都够适配不同国家的插座标准,从而使得一个电器能在各个国家使用。
适配器的思想在程序设计中非常常见,例如代码10-1中就体现了这种思想:
【代码 10-1】
// 方法一
public <K, V> Map<K, V> selectMap(String statement, String mapKey) {
return this.selectMap(statement, null, mapKey, RowBounds.DEFAULT);
}
// 方法二
public <K, V> Map<K, V> selectMap(String statement, Object parameter, String mapKey) {
return this.selectMap(statement, parameter, mapKey, RowBounds.DEFAULT);
}
// 方法三
public <K, V> Map<K, V> selectMap(String statement, Object parameter, String mapKey, RowBounds rowBounds) {
final List<? extends V> list = selectList(statement, parameter, rowBounds);
final DefaultMapResultHandler<K, V> mapResultHandler = new DefaultMapResultHandler<>(mapKey,
configuration.getObjectFactory(), configuration.getObjectWrapperFactory(), configuration.getReflectorFactory());
final DefaultResultContext<V> context = new DefaultResultContext<>();
for (V o : list) {
context.nextResultObject(o);
mapResultHandler.handleResult(context);
}
return mapResultHandler.getMappedResults();
}
上述代码中,方法三是核心方法,它需要四个输入参数。而有些场景下,调用方只能提供三个参数或者两个参数。为了使得只有三个参数或者两个参数的调用方能够正常地调用核心方法,方法一和方法二充当了方法适配器的作用。这两个适配器通过为未知参数设置默认值的方式,搭建起了调用方和核心方法之间的桥梁。
不过,通常我们说起适配器模式是指类适配器或者对象适配器。图10-1给出了类适配器的类图。
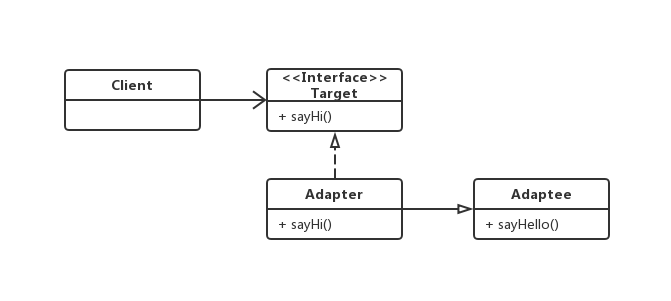
在图10-1中,Target接口是Client想调用的标准接口,而Adaptee是提供服务但不符合标准接口的目标类。Adapter便是为了Client能顺利调用Adaptee而创建的适配器类。如代码10-2所示,Adapter即实现了Target接口又继承了Adaptee类,从而使得Client能够与Adaptee适配。
【代码 10-2】
public class Adapter extends Adaptee implements Target {
@Override
public void sayHi() {
super.sayHello();
}
}
而对象适配器Adaptee不再继承目标类,而是直接持有一个目标类的对象。图10-2给出了对象适配器的类图。

代码10-2便给出了使用对象适配器的示例。
【代码 10-2】
public class Adapter implements Target {
// 目标类的对象
private Adaptee adaptee;
// 初始化适配器时可以指定目标类对象
public Adapter(Adaptee adaptee) {
this.adaptee = adaptee;
}
@Override
public void sayHi() {
adaptee.sayHello();
}
}
这样,Adapter可以直接将Client要求的操作委托给目标类对象处理,也实现了Client和Adaptee之间的适配。而且这种适配器更为灵活一些,因为要适配的目标对象是作为初始化参数传给Adapter的,更为灵活一些。
适配器模式能够使得原本不兼容的类可以一起工作。通常情况下,如果目标类是可以修改的,则不需要使用适配器模式,直接修改目标类即可。但如果目标类是不可以修改的(例如目标类由外部提供,或者目标类被众多其他类依赖必须保持不变),那么适配器模式则会非常有用。
10.1.2 日志框架与日志级别
日志框架是一种在目标对象发生变化时将相关信息记录进日志文件的框架。这样,当目标对象出现问题或需要核查目标对象变动历史时,日志框架记录的日志文件便可以提供详实的资料。
起初,Java的日志打印依靠软件开发者自行编辑输出语句将日志输出到文件流中。例如通过“System.out.println”方法打印普通信息或通过“System.err.println”方法打印错误信息。
开发者自行编辑输出语句进行日志打印的方式非常繁琐,而且还会导致日志格式混乱,不利于日志分析软件的进一步处理。为了解决这些问题,产生了大量的日志框架。
经过多年的发展,Java领域的日志框架已经非常丰富,有log4j、Logging、commons-logging、slf4j、logback等,它们为Java的日志打印工作提供了极大的便利。
为了方便日志管理,日志框架大都对日志等级进行了划分。常见的日志等级划分方式如下:
- FATAL:致命等级的日志,指发生了严重的会导致应用程序退出的事件。
- ERROR:错误等级的日志,指发生了错误,但是不影响系统运行。
- WARN: 警告等级的日志,指发生了异常,可能是潜在的错误。
- INFO: 信息等级的日志,指一些在粗粒度级别上需要强调的应用程序运行信息。
- DEBUG:调试等级的日志,指一些细粒度的对于程序调试有帮助的信息。
- TRACE:跟踪等级的日志,指一些包含程序运行详细过程的信息。
有了以上日志划分后,在打印日志时我们就可以定义日志的级别。而进行日志的输出时也可以根据日志等级进行输出,防止大量的日志信息混杂在一起。目前在很多集成开发环境中可以调节日志的显示级别,使得具有一定级别以上的日志才会显示出来,这样能够根据不同的使用情形进行日志的筛选。图10-3展示了划分了等级的日志在集成开发环境IntelliJ IDEA Community Edition中的展示效果。
10.1.3 基于反射的动态代理
在9.1.3 静态代理章节我们介绍了静态代理。同时我们也提到,静态代理中代理对象和被代理对象是在程序中写死的,不够灵活。具体来说,要想建立某个对象的静态代理,必须要为其建立一个代理类,而且所有被代理的方法需要在代理类中直接调用。这就使得代理类是高度依赖被代理类,被代理类的任何变动都可能引发代理类的变动。
而动态代理则灵活很多,它能在代码运行时动态地为某个对象的增加代理,并且能为代理对象动态地增加方法。
动态代理的实现方式有很多种,这一节我们介绍较为常用的一种:基于反射的动态代理。
在Java中java.lang.reflect包下提供了一个Proxy类和一个InvocationHandler接口,使用它们就可以实现动态代理。
接续9.1.3 静态代理的示例,我们继续通过示例来展示基于反射的动态代理。在该示例中,接口和被代理类与之前一致,没有任何变化。
接口如代码10-3所示。
【代码 10-3】
public interface UserInterface {
String sayHello(String name);
}
被代理类如代码10-4所示。
【代码 10-4】
public class User implements UserInterface {
@Override
public String sayHello(String name) {
System.out.println("hello " + name);
return "OK";
}
}
接下来我们创建一个ProxyHandler类继承java.lang.reflect.InvocationHandler接口,并实现其中的invoke方法。invoke方法中需要传入被代理对象、被代理方法、调用被代理方法所需的参数,如代码10-5所示。
【代码 10-5】
public class ProxyHandler<T> implements InvocationHandler {
private T target;
public ProxyHandler(T target) {
this.target = target;
}
/**
* 代理方法
* @param proxy 代理对象
* @param method 代理方法
* @param params 代理方法的参数
* @return 方法执行结果
* @throws Throwable
*/
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("pre words");
Object ans = method.invoke(target, args);
System.out.println("post words");
return ans;
}
}
接下来我们可以如代码10-6所示,使用动态代理。
【代码 10-6】
public static void main(String[] args) throws Exception {
// 创建被代理对象
User user = new User();
// 初始化一个ProxyHandler对象
ProxyHandler proxyHandler = new ProxyHandler(user);
// 使用Proxy类的一个静态方法生成代理对象userProxy
UserInterface userProxy =
(UserInterface) Proxy.newProxyInstance(
User.class.getClassLoader(),
new Class[] { UserInterface.class },
proxyHandler);
// 通过接口调用相应的方法,实际由Proxy执行
userProxy.sayHello("易哥");
}
该示例的完整代码请参见MyBatisDemo项目中的示例9
得到输出结果:
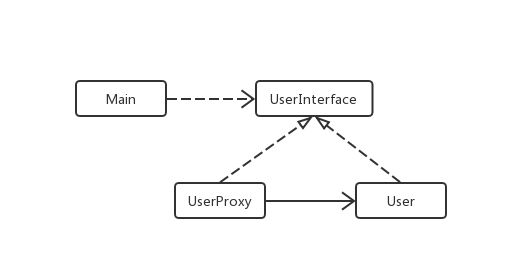
当前示例的类图如下:
动态代理类可以代理多个其他类。例如,在“ProxyHandler proxyHandler = new ProxyHandler(user)”中给ProxyHandler传入不同的被代理对象,然后就可以使用Proxy.newProxyInstance生成不同的代理对象。
本小节示例中的动态代理是基于反射实现的。“Proxy.newProxyInstance”方法通过反射创建了一个实现了“UserInterface”接口的对象,这个对象就是代理对象userProxy。因此对于基于反射的动态代理而言,有一个必须的条件:被代理的对象必须要有一个父接口。
10.2 Log接口
logging包中最重要的就是Log接口,它有11个实现了,分布在logging包的不同子包中。Log接口及其实现类的类图如图10-6所示。

我们先详细了解下Log接口中的方法。Log接口中定义了日志框架要实现的几个基本方法:
- error:打印Error级别日志
- warn:打印Warn级别日志
- debug:打印Debug级别日志
- trace:打印Trace级别日志
- isDebugEnabled:判断打印Debug级别的日志的功能是否开启
- isTraceEnabled:判断打印Trace级别日志的功能是否开启
上述各个方法主要是实现不同级别日志的打印功能。然而,其中的isDebugEnabled方法和isTraceEnabled方法略显突兀,我们单独进行下说明。
isDebugEnabled方法和isTraceEnabled方法是从效率角度考虑而设计的。
首先,Debug和Trace是两个级别比较低的日志,越是低级别的日志越有这样的特点:
- 很少开启:因为它们级别很低,多数时候该级别的信息不需要展示。
- 输出频次高:低级别日志的触发门槛很低,这意味着一旦它们开启,往往会以非常高的频率输出日志信息。
- 内容冗长:它们中往往包含非常丰富和细致的信息,因此信息内容往往十分冗长。
假如存在代码10-7所示的日志打印操作,在日志打印过程中调用了trace方法。以“org.apache.commons.logging.impl.SimpleLog”下的trace方法(可以通过JakartaCommonsLoggingImpl实现类中的trace方法追踪到该方法)为例,其具体实现如代码10-8所示。
【代码 10-7】
trace("Application is : " + appName + "; " +
"Class is : " + className + "; " +
"Function is : " + funcitonName +". " +
"Params : " + params + "; " +
"Return is : " + result +".");
【代码 10-8】
public final void trace(Object message) {
if (this.isLevelEnabled(1)) {
this.log(1, message, (Throwable)null);
}
}
低级别的日志很少开启,这意味着this.isLevelEnabled(1)的返回值大概率是false。因此代码10-7中所示的字符串拼接结果是无用的,会被直接丢弃。并且低级别日志输出频次高且内容冗长,这意味着这种无用的字符串拼接是频发的且资源消耗很大的。
要想避免上述无用的字符串操作导致的大量的系统资源消耗,就需要使用isDebugEnabled方法和isTraceEnabled方法对低级别的日志输出进行前置判断,如代码10-9所示。
【代码 10-9】
if (log.isTraceEnabled()){
trace("Application is : " + appName + "; " +
"Class is : " + className + "; " +
"Function is : " + funcitonName +". " +
"Params : " + params + "; " +
"Return is : " + result +".");
}
这样,借助isTraceEnabled方法就避免了资源的浪费。
在阅读源码的过程中,读懂源码只是完成了浅层知识的学习。在读懂源码的同时思考源码为何这么设计将会使我们有更大收获,而这也会使我们更容易读懂源码。
10.3 Log接口的实现类
在Log接口的11个实现类中,最简单的实现类就是NoLoggingImpl类,因为它是一种不打印日志的实现,内部几乎没有任何的操作逻辑。StdOutImpl实现类也非常简单,对于error级别的日志调用了System.err.println进行打印,而对其他级别的日志调用了System.out.println进行打印。
剩下的9个实现类中,Slf4jLocationAwareLoggerImpl类和Slf4jLoggerImpl类是Slf4jImpl类的装饰器,Log4j2AbstractLoggerImpl类和Log4j2LoggerImpl类是Log4j2Impl类的装饰器。这四个装饰器类结构非常简单,我们不再展开介绍。
接下来我们重点分析剩下的5个实现类,它们是JakartaCommonsLoggingImpl、Jdk14LoggingImpl、Log4jImpl、Log4j2Impl、Slf4jImpl。我们以commons子包中的JakartaCommonsLoggingImpl为例,查看其具体实现。代码10-10是JakartaCommonsLoggingImpl类的部分源码。
【代码 10-10】
public class JakartaCommonsLoggingImpl implements org.apache.ibatis.logging.Log {
private final Log log;
public JakartaCommonsLoggingImpl(String clazz) {
log = LogFactory.getLog(clazz);
}
@Override
public boolean isDebugEnabled() {
return log.isDebugEnabled();
}
@Override
public boolean isTraceEnabled() {
return log.isTraceEnabled();
}
// 省略其他代码
}
可以看出,JakartaCommonsLoggingImpl是一个典型的对象适配器。它的内部持有一个“org.apache.commons.logging.Log”对象,然后所有方法都讲操作委托给了“org.apache.commons.logging.Log”对象。
10.4 LogFactory
我们已经知道Log接口有着众多的实现类,而LogFactory就是制造实现类的工厂。最终,该工厂会给出一个可用的Log实现,由它来完成MyBatis的日志打印工作。
Log接口的实现类都是对象适配器(装饰器类除外),最终的实际工作要委托给被适配的目标对象来完成。因此是否存在一个可用的目标对象成了适配器能否正常工作的关键所在。于是LogFactory的主要工作就是尝试生成各个目标对象。如果一个目标对象能够被生成出来,那该目标对象对应的适配器就是可用的。
LogFactory生成目标对象的工作在静态代码块中被触发。代码10-11展示了LogFactory的静态代码块。
【代码 10-11】
static {
tryImplementation(LogFactory::useSlf4jLogging);
tryImplementation(LogFactory::useCommonsLogging);
tryImplementation(LogFactory::useLog4J2Logging);
tryImplementation(LogFactory::useLog4JLogging);
tryImplementation(LogFactory::useJdkLogging);
tryImplementation(LogFactory::useNoLogging);
}
我们首先查看下代码10-12所示的tryImplementation方法:
【代码 10-12】
/**
* 尝试实现一个日志实例
* @param runnable 用来尝试实现日志实例的操作
*/
private static void tryImplementation(Runnable runnable) {
if (logConstructor == null) {
try {
runnable.run();
} catch (Throwable t) {
// ignore
}
}
}
tryImplementation方法会在logConstructor为null的情况下调用Runnable对象的run方法。要注意一点,直接调用Runnable的run方法并不会触发多线程,因此代码10-11中的多个tryImplementation方法是依次执行的。这也意味着useNoLogging方法中引用的NoLoggingImpl实现是最后的保底实现,而且NoLoggingImpl不需要被适配对象的支持,一定能够成功。因此,最终的保底日志方案就就是不输出日志。
我们以代码10-11中的“tryImplementation(LogFactory::useCommonsLogging)”为例继续追踪源码,该方法通过useCommonsLogging方法调用到了setImplementation方法。代码10-13给出了setImplementation方法的带注释源码。
【代码 10-13】
/**
* 设置日志实现
* @param implClass 日志实现类
*/
private static void setImplementation(Class<? extends Log> implClass) {
try {
// 当前日志实现类的构造方法
Constructor<? extends Log> candidate = implClass.getConstructor(String.class);
// 尝试生成日志实现类的实例
Log log = candidate.newInstance(LogFactory.class.getName());
if (log.isDebugEnabled()) {
log.debug("Logging initialized using '" + implClass + "' adapter.");
}
// 如果运行到这里,说明没有异常发生。则实例化日志实现类成功。
logConstructor = candidate;
} catch (Throwable t) {
throw new LogException("Error setting Log implementation. Cause: " + t, t);
}
}
代码10-13显示setImplementation方法会尝试获取参数中类的构造函数,并用这个构造函数创建一个日志记录器。如果这次创建是成功的,则意味着以后的创建也是成功的,即当前参数中的类是可用的。因此把参数中类的构造方法赋给了logConstructor属性。这样,当外部调用getLog方法时,便可以由logConstructor创建出一个Log类的实例。
在静态代码块中,我们发现StdOutImpl类并没有参与设置logConstructor属性的过程,这是因为它不在默认日志输出方式的备选列表中。不过这并不代表着它毫无用处,因为MyBatis允许我们自行指定日志实现类。例如,我们在配置文件的settings节点下配置如下信息,则可以自定义StdOutImpl类作为日志输出方式,使得MyBatis的日志输出到控制台上。
<setting name="logImpl" value="STDOUT_LOGGING"/>
自行指定日志实现类是在XML解析阶段通过调用LogFactory中的useCustomLogging方法实现的。它相比于静态代码块中的方法执行的更晚,会覆盖前面的操作,因此具有更高的优先级。
10.5 JDBC日志打印
在前面几节的分析中,我们始终对jdbc子包中的源码避而不谈。这是因为jdbc子包中的源码和之前几节的实现逻辑完全不同。在这一节中,我们会对这些源码进行单独的分析。
MyBatis是ORM框架,它负责数据库信息和Java对象的互相映射操作,而不负责具体的数据库读写操作。具体的数据库读写操作是由JDBC进行的,这一点在后面的章节中我们也会详细介绍。
既然MyBatis不进行数据库的查询,那MyBatis的日志中便不会包含JDBC的操作日志。然而,很多时候MyBatis的映射错误是由于JDBC的错误引发的,例如JDBC无法正确执行查询操作或者查询得到的结果类型与预期不一致等。因此,JDBC的运行日志是分析MyBatis框架报错的重要依据。然而,JDBC日志有自身的一套输出体系。JDBC日志和MyBatis日志是分开的,这会给我们的调试工作带来很多的困难。jdbc子包就是用来解决这个问题的。
jdbc子包基于代理模式,让MyBatis能够将JDBC的操作日志打印出来,极大地方便了我们的调试工作。接下来我们就介绍jdbc子包是如何实现这个操作的。
图10-7给出jdbc子包的类图。BaseJdbcLogger作为基类提供了一些子类会用到的基本功能,而其他几个实现类则为相应类提供日志打印能力。例如,ConnectionLogger为“java.sql.Connection”类提供日志打印能力。
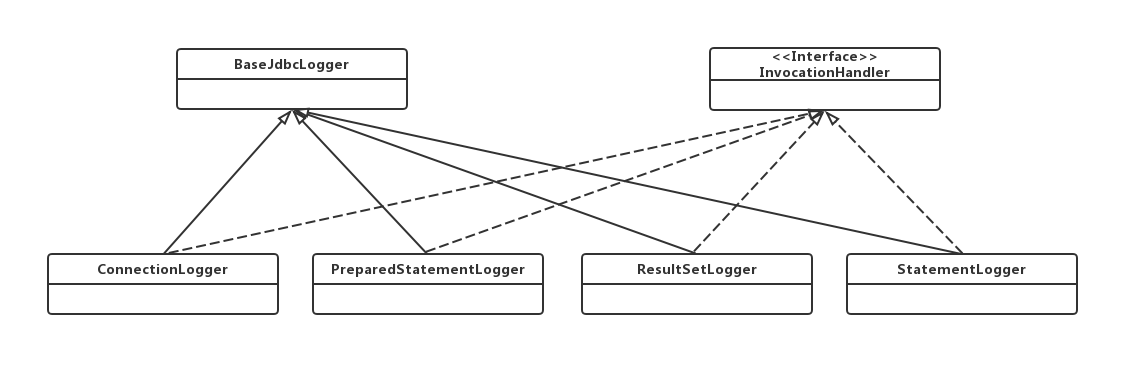
BaseJdbcLogger各个子类使用动态代理来实现日志的打印。以ConnectionLogger为例,介绍BaseJdbcLogger实现类的实现逻辑。
ConnectionLogger继承了InvocationHandler接口,从而成为一个代理类。在BaseExecutor的getConnection方法中我们可以看到代码10-14所示的操作,当statementLog的Debug功能开启时,getConnection返回的不是一个原始的Connection对象,而是由“ConnectionLogger.newInstance”方法生成的一个代理对象。
【代码 10-14】
/**
* 获取一个Connection对象
* @param statementLog 日志对象
* @return Connection对象
* @throws SQLException
*/
protected Connection getConnection(Log statementLog) throws SQLException {
Connection connection = transaction.getConnection();
if (statementLog.isDebugEnabled()) { // 启用调试日志
// 生成Connection对象的具有日志记录功能的代理对象ConnectionLogger对象
return ConnectionLogger.newInstance(connection, statementLog, queryStack);
} else {
// 返回原始的Connection对象
return connection;
}
}
这样,所有“java.sql.Connection”对象的方法调用都会进入ConnectionLogger中的invoke方法中。代码10-15给出了ConnectionLogger中的invoke方法。
【代码 10-15】
/**
* 代理方法
* @param proxy 代理对象
* @param method 代理方法
* @param params 代理方法的参数
* @return 方法执行结果
* @throws Throwable
*/
@Override
public Object invoke(Object proxy, Method method, Object[] params)
throws Throwable {
try {
// 获得方法来源,如果方法继承自Object类则直接交由目标对象执行
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, params);
}
if ("prepareStatement".equals(method.getName())) { // Connection中的prepareStatement方法
if (isDebugEnabled()) { // 启用Debug
// 输出方法中的参数信息
debug(" Preparing: " + removeBreakingWhitespace((String) params[0]), true);
}
// 交由目标对象执行
PreparedStatement stmt = (PreparedStatement) method.invoke(connection, params);
// 返回一个PreparedStatement的代理,该代理中加入了对PreparedStatement的日志打印操作
stmt = PreparedStatementLogger.newInstance(stmt, statementLog, queryStack);
return stmt;
} else if ("prepareCall".equals(method.getName())) { // Connection中的prepareCall方法
if (isDebugEnabled()) { // 启用Debug
debug(" Preparing: " + removeBreakingWhitespace((String) params[0]), true);
}
// 交由目标对象执行
PreparedStatement stmt = (PreparedStatement) method.invoke(connection, params);
// 返回一个PreparedStatement的代理,该代理中加入了对PreparedStatement的日志打印操作
stmt = PreparedStatementLogger.newInstance(stmt, statementLog, queryStack);
return stmt;
} else if ("createStatement".equals(method.getName())) { // Connection中的createStatement方法
// 交由目标对象执行
Statement stmt = (Statement) method.invoke(connection, params);
// 返回一个Statement的代理,该代理中加入了对Statement的日志打印操作
stmt = StatementLogger.newInstance(stmt, statementLog, queryStack);
return stmt;
} else { // 其他方法
return method.invoke(connection, params);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
上述invoke方法主要完成了两个附加的操作:
- 在prepareStatement、prepareCall这两个方法的执行之前增加了日志打印操作。
- 在需要返回PreparedStatement对象、StatementLogger对象的方法中,返回的是这些对象的具有日志打印功能的代理对象。这样,PreparedStatement对象、StatementLogger对象中的方法操作也可以打印日志。
BaseJdbcLogger的其他几个实现类的逻辑与ConnectionLogger的实现逻辑完全一致,留给大家自行阅读分析。
22.3 懒加载功能
22.3.1 懒加载功能的使用
在我们进行跨表数据查询的时候,常出现先查询表A、再根据表A的输出结果查询表B的情况。而有些时候,我们从A表中查询出来的数据中,只有部分需要查询B表。
例如我们需要从user表查询用户信息并打印所有用户的姓名列表。而查询出的用户中,只有满足“user.getAge() == 18”的用户才需要查询该用户在task表中的信息。这个过程如代码22-24所示。
【代码 22-24】
User userParam = new User();
userParam.setSex(0);
// 查询满足条件的全部用户
List<User> userList = session.selectList("com.github.yeecode.mybatisdemo.dao.UserDao.lazyLoadQuery", userParam);
// 打印全部用户姓名列表
System.out.println("users: ");
for (User user : userList) {
System.out.println(user.getName() + ", age = " + user.getAge());
}
// 根据条件打印用户任务信息
System.out.println("userDetail: ");
for (User user : userList) {
if (user.getAge() == 18) {
System.out.println(user.getName() + ":");
for (Task task : user.getTaskList()) {
System.out.println(task.getTaskName());
}
}
}
在代码22-24所示的情况下,我们可以先从user表获取用户信息,然后再从task表查询所有用户的任务信息。这一定是可行的,但是这样操作会查询出许多多余的结果,所有不满足“user.getAge() == 18”的用户的任务信息都是多余的。
一种更好的方案是先从user表获取用户信息,然后根据需要(即是否满足“user.getAge() == 18”)决定是否查询该用户在task表中的信息。
这种先加载必须的信息,然后再根据需要进一步加载信息的方式叫作懒加载。MyBatis便支持数据的懒加载。
要想使用懒加载,我们需要在MyBatis的配置文件中启用该功能,如代码22-25所示。
【代码 22-25】
<settings>
<!--全局启用懒加载-->
<setting name="lazyLoadingEnabled" value="true" />
<!--激进懒加载设置 false即:懒加载时,每个属性都按需加载-->
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
aggressiveLazyLoading是激进懒加载设置,我们对该属性进行一些说明。当aggressiveLazyLoading设置为true时,对对象任一属性的读或者写操作都会触发该对象所有懒加载属性的加载;当aggressiveLazyLoading设置为false时,对对象某一懒加载属性的读操作会触发该属性的加载。无论aggressiveLazyLoading的设置如何,调用对象的”equals”,”clone”,”hashCode”,”toString”中任意一个方法都会触发该对象所有懒加载属性的加载。在后面的源码阅读中,我们会清晰地看到aggressiveLazyLoading设置项如何生效。
接下来我们还需要设置好映射文件,如代码22-26所示。在“id="lazyLoadQuery"”的查询中,查询user表是必须的操作,而在结果的映射中又需要查询task表,因此它涉及到两个表的查询。而只要不访问User对象的taskList属性,则task表的查询操作就是可以省略的。因此,User对象的taskList就是可以懒加载的属性。
【代码 22-26】
<resultMap id="associationUserMap" type="User">
<result property="id" column="id"/>
<result property="name" column="name"/>
<result property="email" column="email"/>
<result property="age" column="age"/>
<result property="sex" column="sex"/>
<result property="schoolName" column="schoolName"/>
<association property="taskList" javaType="ArrayList" select="com.github.yeecode.mybatisdemo.dao.UserDao.selectTask" column="id"/>
</resultMap>
<select id="lazyLoadQuery" resultMap="associationUserMap">
select * FROM `user` WHERE `sex` = #{sex}
</select>
<select id="selectTask" resultType="Task">
select * FROM `task` WHERE `userId` = #{id}
</select>
这样运行代码22-24所示的查询操作,可以看到控制台打印出图22-19所示的输出。
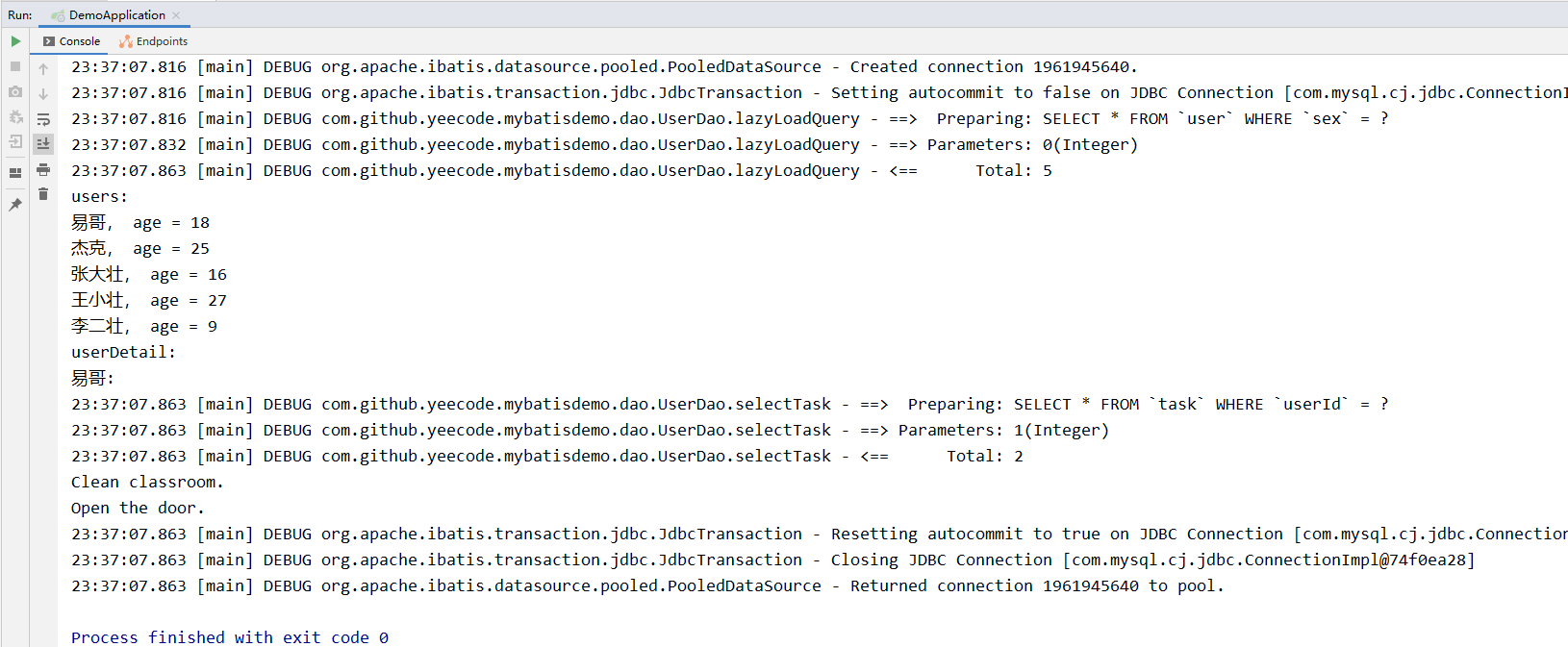
可以看出MyBatis先从user表查询了所有的用户信息,然后仅对满足“user.getAge() == 18”的“易哥”调用了selectTask语句从task表查询了任务信息,而没有对不符合条件的“杰克”等人调用selectTask语句。因此,整个过程是存在懒加载的。
该示例的完整代码请参见MyBatisDemo项目中的示例24
MyBatis懒加载的实现由executor包的loader子包支持。
22.3.2 懒加载功能的实现
22.3.2.1 懒加载功能框架
懒加载功能的实现还是相对复杂的,为便于理解,我们先简要给出MyBatis中懒加载的实现原理,这对我们后面的源码阅读有着重要的帮助。
以我们在22.3.1 懒加载功能的使用章节中介绍的示例为例,整个懒加载过程可以简化如下:
- 先查询user表,获得User对象。
- 将返回的User对象替换为User对象的代理对象UserProxy对象,并返回给上层应用。UserProxy对象有以下特点:
- 当属性的写方法被调用时,直接将属性值写入被代理对象
- 当属性的读方法被调用时,判断是否为懒加载属性。如果不是懒加载属性,直接由被代理对象返回;如果是懒加载属性,则根据配置加载该属性,然后再返回。
上述只是一个经过抽象的简化过程,实际的懒加载原理要复杂许多。图22-20给出了loader子包中核心类的类图:

在了解了懒加载的基本实现原理之后,我们参照loader子包的类图对懒加载功能中涉及的类进行源码阅读。
22.3.2.2 代理工厂
ProxyFactory是创建代理类的工厂接口,其中的setProperties方法用来对工厂进行属性设置,但是MyBatis内置的两个实现类均没有实现该接口,故不支持属性设置。createProxy方法用来创建一个代理对象。
ProxyFactory接口有两个实现,即CglibProxyFactory和JavassistProxyFactory。这两个实现整体结构高度一致,甚至内部类、方法设置都一样,只是实现原理上不同,一个是基于cglib实现,另一个是基于Javassist实现。接下来我们以CglibProxyFactory为例进行源码分析。
CglibProxyFactory中提供了两个创建代理对象的方法。其中createProxy方法重写了ProxyFactory接口中的方法,用来创建一个普通的代理对象。createDeserializationProxy用来创建一个反序列化的代理对象,对于反序列化代理对象的作用和实现,我们在22.3.3 懒加载功能对序列化和反序列化的支持节单独介绍,这里先略过。
createProxy方法创建的代理对象是内部类EnhancedResultObjectProxyImpl的实例。我们首先看一下EnhancedResultObjectProxyImpl内部类的属性,如代码22-27所示。
【代码 22-27】
// 被代理类
private final Class<?> type;
// 要懒加载的属性Map
private final ResultLoaderMap lazyLoader;
// 是否是激进懒加载
private final boolean aggressive;
// 能够触发全局懒加载的方法名“equals”, “clone”, “hashCode”, “toString”。这四个方法名在Configuration中被初始化。
private final Set<String> lazyLoadTriggerMethods;
// 对象工厂
private final ObjectFactory objectFactory;
// 被代理类构造函数的参数类型列表
private final List<Class<?>> constructorArgTypes;
// 被代理类构造函数的参数列表
private final List<Object> constructorArgs;
代理类中最核心的方法是intercept方法。当被代理类的方法被调用时,都会被拦截进该方法。在介绍intercept方法方法之前,我们先了解两个方法:finalize方法和writeReplace。因为在intercept方法中,对这两种方法进行了排除。
- finalize方法:在JVM进行垃圾回收前,允许使用finalize方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。该是由垃圾收集器在确定这个对象没有被引用时对这个对象调用的。
- writeReplace方法:背景知识22.1.3.2 writeReplace方法和readResolve方法中已经介绍。
下面我们阅读下EnhancedResultObjectProxyImpl类中intercept方法的源码,如代码22-28所示。
【代码 22-28】
/**
* 代理类的拦截方法
* @param enhanced 代理对象本身
* @param method 被调用的方法
* @param args 每调用的方法的参数
* @param methodProxy 用来调用父类的代理
* @return 方法返回值
* @throws Throwable
*/
@Override
public Object intercept(Object enhanced, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
// 取出被代理类中此次被调用的方法的名称
final String methodName = method.getName();
try {
synchronized (lazyLoader) { // 防止属性的并发加载
if (WRITE_REPLACE_METHOD.equals(methodName)) { // 被调用的是writeReplace方法
// 创建一个原始对象
Object original;
if (constructorArgTypes.isEmpty()) {
original = objectFactory.create(type);
} else {
original = objectFactory.create(type, constructorArgTypes, constructorArgs);
}
// 将被代理对象的属性拷贝进入新创建的对象
PropertyCopier.copyBeanProperties(type, enhanced, original);
if (lazyLoader.size() > 0) { // 存在懒加载属性
// 则此时返回的信息要更多,不仅仅是原对象,还有相关的懒加载的设置等信息。因此使用CglibSerialStateHolder进行一次封装
return new CglibSerialStateHolder(original, lazyLoader.getProperties(), objectFactory, constructorArgTypes, constructorArgs);
} else {
// 没有未懒加载的属性了,那直接返回原对象进行序列化
return original;
}
} else {
if (lazyLoader.size() > 0 && !FINALIZE_METHOD.equals(methodName)) { // 存在懒加载属性且被调用的不是finalize方法
if (aggressive || lazyLoadTriggerMethods.contains(methodName)) { // 设置了激进懒加载或者被调用的方法是能够触发全局加载的方法
// 完成所有属性的懒加载
lazyLoader.loadAll();
} else if (PropertyNamer.isSetter(methodName)) { // 调用了属性写方法
// 则先清除该属性的懒加载设置。该属性不需要被懒加载了
final String property = PropertyNamer.methodToProperty(methodName);
lazyLoader.remove(property);
} else if (PropertyNamer.isGetter(methodName)) { // 调用了属性读方法
final String property = PropertyNamer.methodToProperty(methodName);
// 如果该属性是尚未加载的懒加载属性,则进行懒加载
if (lazyLoader.hasLoader(property)) {
lazyLoader.load(property);
}
}
}
}
}
// 触发被代理类的相应方法。能够进行到这里的是除去writeReplace方法外的方法,例如读写方法、toString方法等
return methodProxy.invokeSuper(enhanced, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
接下来我们分析一下intercept方法的实现逻辑。其中被代理对象的writeReplace方法被调用的情况,我们会在22.3.3 懒加载功能对序列化和反序列化的支持节单独介绍。被代理对象的finalize方法被调用时,代理对象不需要做任何特殊处理。
而被代理对象的其他方法被调用时,intercept方法的处理方式如下:
- 如果设置了激进懒加载或者被调用的是触发全局加载的方法,则直接加载所有未加载的属性。
- 如果被调用的是属性写方法,则将该方法从懒加载列表中删除,因为此时数据库中的数据已经不是最新的,没有必要再去加载。然后进行属性的写入操作。
- 如果被调用的是属性读方法。则如果该属性尚未懒加载的话,加载该属性;如果该属性已经懒加载过,则直接读取该属性。
以上整个逻辑和我们在章节初给出的简化逻辑基本一致,只是在细节上考虑了更多的情况。
22.3.2.3 ResultLoaderMap类
被代理对象可能会有多个属性可以被懒加载,这些尚未完成加载的属性是在ResultLoaderMap类的实例中存储的。ResultLoaderMap主要就是一个HashMap,该HashMap中的键为属性名的大写,值为LoadPair对象。
LoadPair类是ResultLoaderMap类的内部类,它能够实现对应属性的懒加载操作。我们首先看一下代码22-29给出的LoadPair的属性。
【代码 22-29】
// 用来根据反射得到数据库连接的方法名
private static final String FACTORY_METHOD = "getConfiguration";
// 判断是否经过了序列化的标志位,因为该属性被设置了transient,经过一次序列化和反序列化后会变为null
private final transient Object serializationCheck = new Object();
// 输出结果对象的封装
private transient MetaObject metaResultObject;
// 用以加载未加载属性的加载器
private transient ResultLoader resultLoader;
// 日志记录器
private transient Log log;
// 用来获取数据库连接的工厂
private Class<?> configurationFactory;
// 该未加载的属性的属性名
private String property;
// 能够加载未加载属性的SQL的编号
private String mappedStatement;
// 能够加载未加载属性的SQL的参数
private Serializable mappedParameter;
指定属性的加载操作由LoadPair中的load方法来完成,其带注释的源码如代码22-30所示。
【代码 22-30】
/**
* 进行加载操作
* @param userObject 需要被懒加载的对象(只有当this.metaResultObject == null || this.resultLoader == null才生效,否则会采用属性metaResultObject对应的对象)
* @throws SQLException
*/
public void load(final Object userObject) throws SQLException {
if (this.metaResultObject == null || this.resultLoader == null) { // 输出结果对象的封装不存在或者输出结果加载器不存在
// 判断用以加载属性的对应的SQL语句存在
if (this.mappedParameter == null) {
throw new ExecutorException("Property [" + this.property + "] cannot be loaded because "
* "required parameter of mapped statement ["
* this.mappedStatement + "] is not serializable.");
}
final Configuration config = this.getConfiguration();
// 取出用来加载结果的SQL语句
final MappedStatement ms = config.getMappedStatement(this.mappedStatement);
if (ms == null) {
throw new ExecutorException("Cannot lazy load property [" + this.property
* "] of deserialized object [" + userObject.getClass()
* "] because configuration does not contain statement ["
* this.mappedStatement + "]");
}
// 创建结果对象的包装
this.metaResultObject = config.newMetaObject(userObject);
// 创建结果加载器
this.resultLoader = new ResultLoader(config, new ClosedExecutor(), ms, this.mappedParameter,
metaResultObject.getSetterType(this.property), null, null);
}
// 只要经历过持久化,则可能在别的线程中了。为这次惰性加载创建的新线程ResultLoader
if (this.serializationCheck == null) {
final ResultLoader old = this.resultLoader;
this.resultLoader = new ResultLoader(old.configuration, new ClosedExecutor(), old.mappedStatement,
old.parameterObject, old.targetType, old.cacheKey, old.boundSql);
}
this.metaResultObject.setValue(property, this.resultLoader.loadResult());
}
上述方法的设计包含很多非常巧妙的点,我们一一进行介绍。
首先,懒加载的过程就是执行懒加载SQL语句后,将查询结果使用输出结果加载器赋给输出结果元对象的过程。因此,load方法首先会判断输出结果元对象metaResultObject和输出结果加载器resultLoader是否存在。如果不存在的话,会使用入参userObject重新创建上述两者。
然后,我们介绍ClosedExecutor类的设计。ClosedExecutor类是ResultLoaderMap的内部类。该类只有一个isClosed方法能正常工作,其他所有的方法都会抛出异常。然而就是一个这样的类,在创建ResultLoader时还被使用,如代码22-31所示。
【代码 22-31】
this.resultLoader = new ResultLoader(config, new ClosedExecutor(), ms, this.mappedParameter,
metaResultObject.getSetterType(this.property), null, null);
这是因为ClosedExecutor类存在的目的就是通过isClosed方法返回true来表明自己是一个关闭的类,以保证让任何遇到ClosedExecutor对象的操作都会重新创建一个新的有实际功能的Executor。例如在ResultLoader中我们可以找到代码22-32所示的源码。
【代码 22-32】
// 初始化ResultLoader时传入的执行器
Executor localExecutor = executor;
if (Thread.currentThread().getId() != this.creatorThreadId || localExecutor.isClosed()) {
// 执行器关闭,或者执行器数据其他线程,则创建新的执行器
localExecutor = newExecutor();
}
可以看出,传入的ClosedExecutor对象总会触发ResultLoader创建新的Executor对象。所以,没有任何实际功能的ClosedExecutor对象起到了占位符的作用。
最后,我们介绍load方法中与序列化和反序列化相关的设计。
经过一次序列化和反序列化后,对象可能处在了全新的线程中;序列化和反序列化的时间间隔可能很长,原来的缓存信息也极有可能没有了意义。这些情况都需要懒加载过程进行特殊的处理。
我们知道,在继承了Serializable接口的类中,如果对某个属性使用transient关键字修饰,就会使得序列化操作忽略该属性。那对序列化的结果进行反序列化时,就会导致该属性变为null。基于此,LoadPair中的serializationCheck属性被设计成了一个序列化标志位。只要LoadPair对象经历过序列化和反序列化过程,就会使得serializationCheck属性的值变为null。
如果经历过序列化与反序列化,则当前的LoadPair对象很有可能处在一个新的线程之中。因此继续使用之前的ResultLoader可能会引发多线程问题。所以,LoadPair对象只要检测出自身经历过持久化,就会依赖老ResultLoader对象中的信息重新创建一个新ResultLoader对象。该过程参照代码22-30。
ResultLoader对象也被transient修饰,因此真正老ResultLoader对象也才序列化和反序列化的过程中消失了,与之一起消失的还有MetaObject对象和ResultLoader对象。因此这里所谓的老ResultLoader对象实际是在该load方法中进入“(this.metaResultObject == null || this.resultLoader == null)”对应的分支后重新组建的。该过程参照代码22-30。
而重新组建的所谓的老ResultLoader对象与真正的老ResultLoader对象相比缺少了cacheKey和boundSql这两个参数。其中cacheKey是为了加速查询而存在,非必要并且缓存可能早已失效;而boundSql会在后面的查询阶段重新补足,在BaseStatementHandler的构造方法中就可以找到相关的代码片段。
这样,序列化和反序列化引入的问题才被一一解决了。可见,牵涉到序列化和反序列化之后,懒加载操作会变得十分复杂。
22.3.2.4 ResultLoader类
ResultLoader是一个结果加载器类,它负责完成数据的加载工作。因为懒加载只涉及查询,而不需要支持增、删、改的工作,因此它只有一个查询方法selectList来进行数据的查询。
试读章节结束。
书籍购买地址: 京东