什么是一致性Hash算法?
保留所有版权,请引用而不是转载本文(原文地址 https://yeecode.top/blog/17/ )。
Hash算法
说起Hash算法,我们都是熟悉的,它是一种摘要算法,即根据原有的内容产生一个简短的摘要结果。摘要结果跟原内容是相关的,原内容的改变(极大概率)会导致摘要内容的改变。这里说的极大概率会改变是因为这取决于该Hash算法的输出空间的大小:输出空间小了,则可能出现改变后的Hash结果与原Hash结果恰好相等的情况;而输出空间越大,上述情况发生的概率则越小。
假设输入输出都是一个数字,那么我们可以定义一个简单的Hash算法:
private final int size = 7;
public int simpleHash(int value) {
return value%size;
}
当一个值value输入时,该算法会输出0到6之间的自然数。
Hash算法的使用与问题
Hash算法的使用非常广泛,例如对一段信息生成Hash值后,可以作为校验信息是否发生变更的依据;通过Hash算法,将请求均匀地分配到应用服务器上;使用Hash算法,确保同样的用户总是访问同一个服务器等。
但是,Hash算法也存在一定的局限性。例如,我们有0-6共7台服务器,通过我们上一节的Hash算法将用户id(自然数)作为输入,得到一个服务器编号。然后将用户的信息近似均匀地分配到这7台服务器上,从而实现负载均衡。
假如这时5号服务器出现故障,我们要将其下线,于是:
private final int size = 6;
这时我们发现,用户id输入后,该Hash算法输出的结果与原来相差极大,使得大量用户无法访问到原来的服务器,这并不是我们想见到的。例如,28号用户,原来28%7=0,映射到0号服务器,现在则映射到了28%6=4,映射到了4号服务器。而原来的0号服务器是存在的,该28号用户应依旧分配到0号服务器才对。
当然,随着用户增多,我们增加一台服务器时,也会引发相同的问题。此时一般需要进行重新Hash操作,对各个服务器上的数据进行重新分配,此操作几乎涉及所有服务器上的所有数据,工作量极大。
一致性Hash算法
在分布式系统中,扩容缩容操作极为常见,如果频繁进行重Hash操作显然是不可取的,一是消耗太大,而是可能引发服务的中断。此时,就要采用一致性Hash算法。
一致性Hash算法(Consistent Hashing)是一种hash算法,它能够在Hash输出空间发生变化时,引起最小的变动。以我们的例子来讲,增加或者移除一台服务器时,对原有的服务器和用户之间的映射关系产生的影响最小。
好的一致性Hash算法应该能够满足以下要求:
- 平衡性:这是Hash算法的基本要求,是指哈希的结果均匀地分配在整个输出空间中。
- 单调性:当发生数据节点变动时,对于相同的数据始终映射到相同的缓冲节点中或者新增加的缓冲节点中,避免无法找到原来的数据。
- 稳定性:当出现节点坏掉或热点访问而需要动态扩容时,尽量减少数据的移动。显然一般的Hash方法不满足这一点。
原理
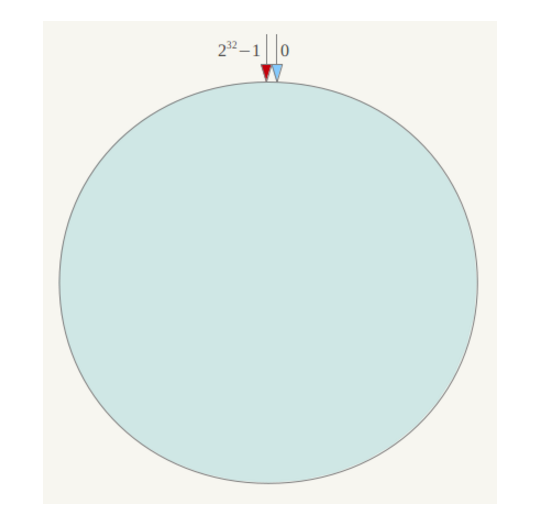
一致性哈希算法最早在论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中提出。具体思路就是一致性哈希将整个哈希输出空间设置为一个环形区域。例如,该环形区域用数字0-2^32-1表示,沿顺时针方向值不断增大,0与2^32重合。整个哈希空间环如下:
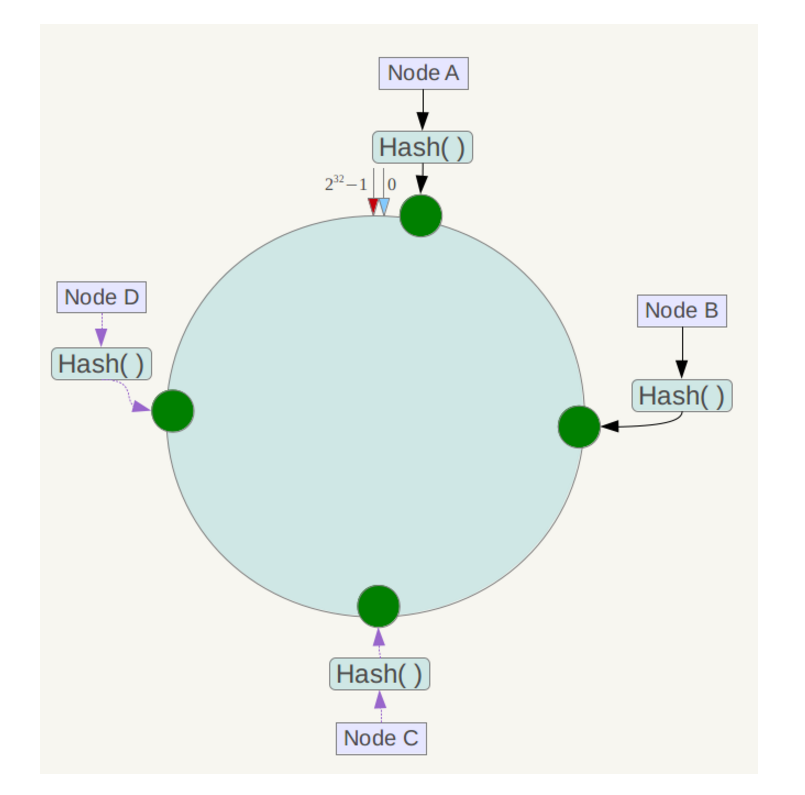
接下来,我们将服务器进行Hash。可以使用服务器的编号或者ip等作为输入,得到一个输出值,映射在输出空间的环形区域上。假设它们的位置如下:
对于用户数据,同样进行Hash操作,映射在环形区域上。然后,让该值沿着顺时针方向移动,遇到的第一个服务器就是它分配的服务器。例如有A、B、C、D四个数据对象,经过一致性哈希计算后,在环空间上的位置如下:
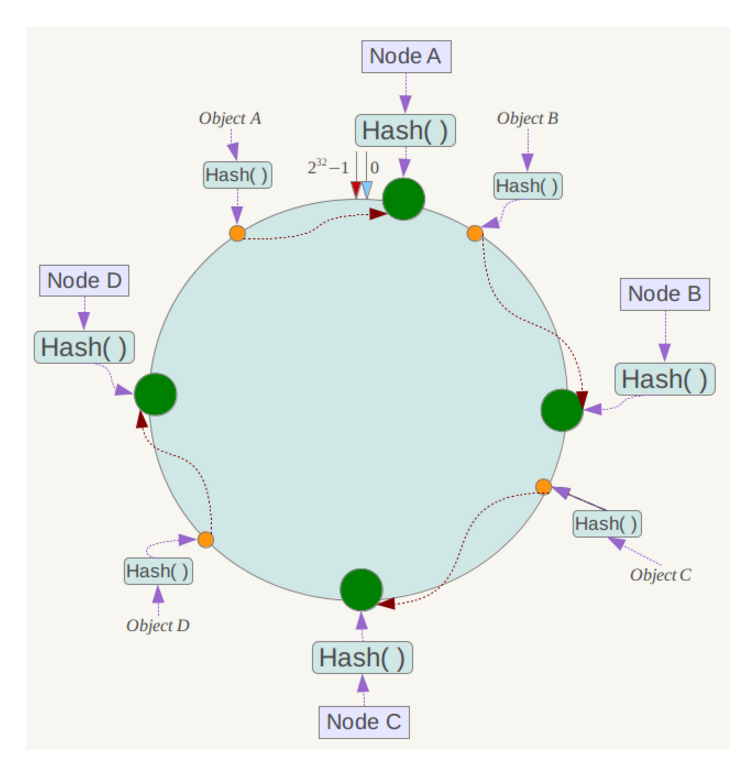
则根据刚才的规则,数据A会被分配到Node A上,B被分配到Node B上,C被分配到Node C上,D被分配到Node D上。
可以访问个人知乎阅读更多文章:易哥(https://www.zhihu.com/people/yeecode),欢迎关注。
作者书籍推荐


