如何入门Python爬虫?
保留所有版权,请引用而不是转载本文(原文地址 https://yeecode.top/blog/35/ )。
今天我们就从最基本和最本质的途径去编写一个爬虫,让大家真正了解爬虫的工作原理。并且,能够在此基础上根据自身需求改造出需要的爬虫。
绝对基础、绝对易懂、绝对能上手。如果看完还不会写,我给你表演100个俯卧撑!
主要内容分为以下几个部分:
1、被爬取对象
2、当前对象的爬取
3、顺藤摸瓜的实现
4、取来即用的最简单框架
1、被爬取对象
爬虫是在从网络上爬取内容,常见的爬取的内容由:
- 网页本身
- 网站接口给出的数据
- 网站中的图片、视频等特定资源
其中最基本最原始的就是爬取网页本身。如果我们会爬取网页,那接口的数据也会被带出来,特定的资源也可以被筛选出来。因此,我们以爬取网页为例进行介绍。
那我们先了解什么是网页。例如,下面就是一个网页的截图。
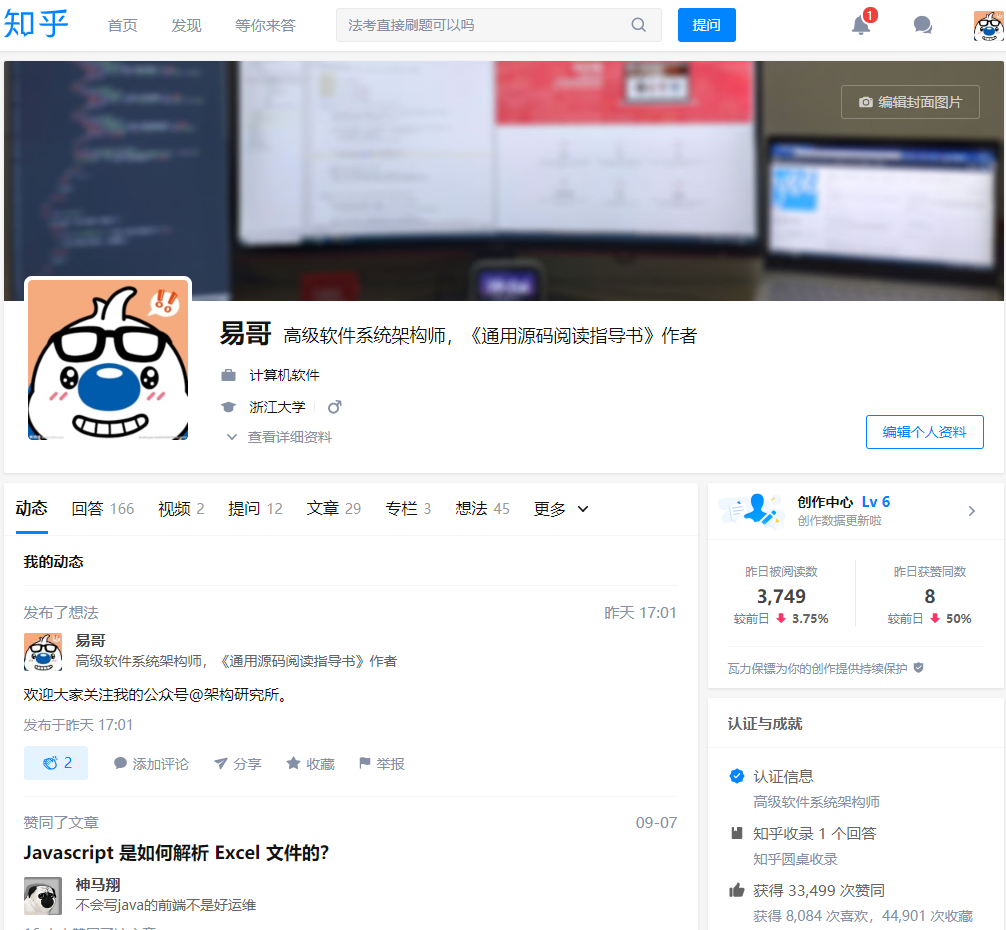
那这个网页是怎样构成的呢?
我们在网页上点击右键,选择“查看网页源代码”。
就看到了下面的内容,乱糟糟的一片。

正是这乱糟糟的一片,经过浏览器渲染后,便成了眼前的页面。这东西就叫做网页源代码,是HTML文件。
我们可以在其中找到很多的元素。
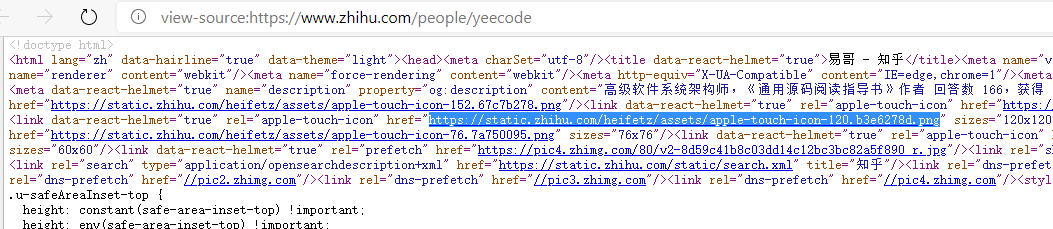
例如,下面的是该网页的主旨,主要是给搜索引擎看的:

下面这段则指向了一张图片的地址,渲染时浏览器会去下载和展示这张图片:
下面这个则指向了一个后缀为css的文件。CSS文件是网页的样式文件,负责修饰网页上内容的样式(长宽高、间距、背景颜色等):
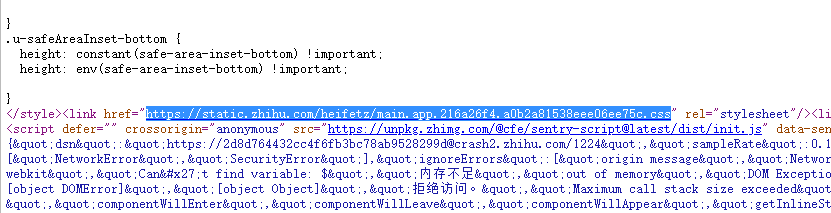
下面这个则指向了一个后缀为js的文件。JS文件即javascript文件,负责为网页提供一些动态的响应功能、逻辑处理功能。例如一些点击后的操作逻辑都是由它实现的:

还有非常重要的一部分,就是超链接。它指向了另外一个网页的地址。我们通过它,可以跳转到另外一个页面。

另外还有很多元素,都是界面上会显示的内容。
可见,HTML文件很重要,它包含了:
- 当前页面要显示的内容
- 修饰当前页面样式的CSS文件的地址
- 为当前页面提供逻辑处理功能的JS文件的地址
- 当前页面中图片视频等资源的地址
- 通过当前页面能够跳转到的其他页面的地址
可见它十分重要。
浏览器在工作时就是先下载指定地址的HTML文件,然后再根据HTML文件中给出的CSS、JS等资源连接去下载相关资源。可见,HTML文件是核心。
而一个网页的组成部分我们也理清楚了,如下图所示。
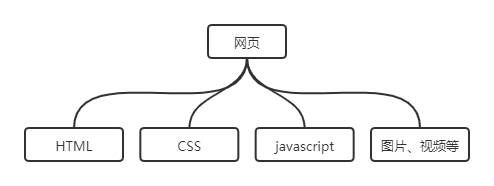
我们在爬取时,会根据不同部分进行不同处理:
- HTML文件:因为其中包含有网页上要显示的内容,因此这是爬虫爬取的重点内容。
- CSS文件:用来修饰样式,一般没什么具体信息,不去爬取
- Javascript:也没什么信息,不去爬取
- 图片、视频等:如果我们是爬文字,则忽略他们。如果我们想专门爬取图片,则要爬取这些内容。
好,对被爬取对象的分析就到这里。
2、当前对象的爬取
假如我们已经有了某个页面的地址,怎么爬取其中的内容呢?
其实很简单,我们将Python程序伪装为一个浏览器,向网站请求数据。那网站自然就会将HTML信息发送给我们。我们可以将其保存在一个文本文件中。
下面的代码就可以实现。
htmlFile=open('./output/'+(str(pageId)+'.txt'),'w')
htmlFile.write(urllib.urlopen(url).read())
htmlFile.close()
是不是很简单!
3、顺藤摸瓜的实现
爬虫,有一个重要的点是“爬”。能顺藤摸瓜地爬到下一个地方,继续下载。怎么实现?
还记得么,我们已经在第二步中下载了当前页面的HTML文件。而在第一步中我们说过,HTML文件中有到其他页面的链接!
那我们要做的就是将这些到其他页面的链接找出来,然后到对应的页面下载相关内容。简单!
怎么找出来呢?正则表达式!简单来说,就是按照一定的格式在文本中寻找。
在HTML文件中,指向其它网页的地址是放在”href=“后面的,而且我们也说过,网页的地址一定不是css、js等结尾的文件,也不是图片(ico、jpg等结尾的就是图片)。
所以,我们可以粗略地使用下面的表达式将链接过滤出来。
pattern=re.compile('href="[^(javascript)]\S*[^(#)(css)(js)(ico)]\"')
然后我们就可以将过滤出来的链接内容下载下来(即再次执行第二步),然后继续分析(再次执行第三步)……然后一直爬呀爬……
这时我们可以增加一些新的规则,例如,不仅仅下载HTML文件,顺便现在其中的图片等。做到爬图功能。
4、整体流程
好了,爬虫已经不难了。
简单来说就是下面的步骤:
爬取函数(a)
下载网页a的内容
分析网页a中的链接,对得到的每一个链接b调用 爬取函数(b)
当然,这个过程中也要处理一些小的细节。例如:
- 遇到坏掉的链接要跳过,不要一直等待
- 遇到已经下载过的链接要跳过,否则会形成环路,永远无法退出
5、取来即用的爬虫框架
好了,接下直接实现一个最简单的框架,地址如下:
https://github.com/yeecode/EasyCrawler
最基本最简单的Python爬虫示例,适合初学者了解爬虫的工作原理和实现,并在此基础上增加功能。
该爬虫的基本功能如下:
- 输入一个入口地址后,会爬取该地址网页中href=指向的页面,并将内容下载下来,依次保存
- 对于不能访问的坏链接,将会忽略
- 该爬虫只能爬取入口地址的链接,不再向更深处爬取
- 会自动给页面编ID,并跳过已爬取的页面
整个示例极少依赖外部项目,十分简单、易懂、纯粹。因此该项目不仅便于学习,也便于在此基础上扩充改装。
基于以上功能,我们可以修改实现众多其他功能,包括但不限于:
- 根据页面不断爬取,而不是只爬取一层链接
- 设置爬取范围,例如只爬取某个域名下的链接
- 定时爬取某个地址的数据,并对比其变化
- 只爬取网页中的图片信息
等等……
最后,给一个这个爬虫工作的视频,在下面回答的最后方,【点击这里】。
可以访问个人知乎阅读更多文章:易哥(https://www.zhihu.com/people/yeecode),欢迎关注。
作者书籍推荐

