什么是湖仓一体?它有什么意义?
保留所有版权,请引用而不是转载本文(原文地址 https://yeecode.top/blog/45/ )。
看到阿里的湖仓一体,突然想起当时做大数据算法开发时,最怕的事情就是上线。
上线后的第一次运行,十有八九会异常。
那时最常用的还是Hadoop,往往一个任务跑了十几个小时后,总在Mapper到达99.9%的时候宕掉。
不是前期测试的不充分,而是无论如何,前期的测试数据集也无法覆盖真实数据的所有异常。然后,只要遗漏一个点,Mapper就会在最后宕掉。前功尽弃,只能重来。要是赶上工期紧,光吓就能吓个半死。
要想用全量的真实数据做前期验证是不可能的,因为任务所需要的数据往往在不同的地方,且常常数T大小。一是搬不动,二是没地放。因此,很多时候,只能从各处搬运一点数据出来做测试,数据量十分有限。
就别说是开发和测试了,就连算法最终上线后,还要系统专门进行数据搬运。对的,一般我们算法团队产出的是按照规定格式生成的文本文档,没法直接给应用使用。需要系统数据转移模块中的定时任务将其搬运到数据库中,才能在明天供应用使用。
那时就是这样的:开发时搬运数据的工作量大;上线后运行的故障率高;线上系统需要完成数据搬运工作;算法结果往往次日才能入库生效。
大家倒也习以为常,“我们做的就是大数据开发,数据量大,搬来搬去浪费些时间也正常。”
是的,数据量大,搬来搬去浪费些时间当然正常。
可是,真的需要搬来搬去么?
今天我们就来聊一聊。
1 数据湖与数据仓库
很多人说起大数据,对它的印象就是“大”,然后没然后了。但其实不然,大数据也分很多种,通常我们可以通过两个维度来衡量它:结构化程度和信息密度。
数据的结构化程度描述的是数据本身的规范性。例如传统数据库中的数据主要是结构化的,每条记录包含了众多的字段,每个字段是一个独立的信息块。而邮件正文、发言稿件等这些信息就是非结构化的,它没有结构化的格式来约束其中的信息。
数据的信息密度描述的是单位存储体积内包含的信息量的大小。显然,传统数据库中存储的数据的信息密度是很高的,例如性别字段中的0、1就用很小的存储体积标明了一个明确的信息。而邮件正文、发言稿的信息密度是低的,有很多重复的语句,语句中也夹杂很多意义不大的词语甚至可能还有歧义。
大数据处理的过程其实是一个提升数据的结构化程度和信息密度的过程:
- 获取到的原始数据往往是非结构化的、信息密度很低的;
- 然后通过数据清洗、分析等等,排除无用的数据、挖掘数据中的关联,不断提升其结构化程度、信息密度;
- 最后,得到结构化程度较高、信息密度较高的结果,加以利用。
整个过程中,信息的发展如下所示:
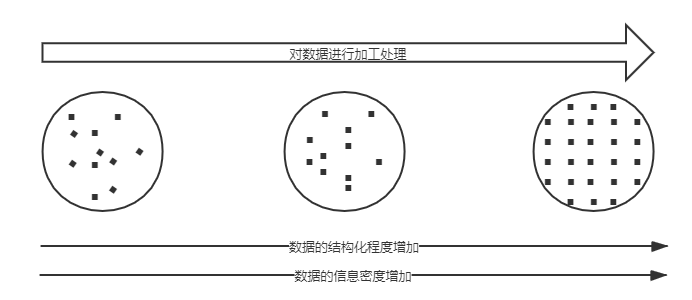
其实这时我们可以发现,在大数据的处理过程中,其特征在一直变化。而不同的数据,其适宜的存储介质也是不同的。这就引出了数据湖和数据仓库的概念。
1.1 什么是数据湖
数据湖适合存储非结构化的、信息密度低的、未经清洗的数据。例如生产中我们获取到的日志信息、长文本信息等都可以直接放到数据湖中。例如Hive、Spark等都属于这一类。
“湖”字将它的特点体现的淋漓尽致。水,纳百川,而无形。几乎任何数据都可以往里放,但也因为没有太多规范,里面很杂乱。
数据湖就像是办公桌子上的对其的文档,有一些事笔记,有一些是书本,有一些是打印的材料,杂乱、多样,但是使用起来很方便,你可以从中挑选你喜欢的数据随意组合。

数据湖的这种开放性非常有利于前期的开发、创造。毕竟据说,人的桌子越乱,就越有创造力。数据湖里杂乱的数据就是创造力的象征。
1.2 什么是数据仓库
数据仓库适合存储结构化的、信息密度高的、经过处理后的数据。例如我们通过大数据分析得到的关联信息、画像信息等,都可以放在数据仓库中。例如BigQuery、MaxCompute都属于这一类。
“仓库”一词也将它的特点表现的清清楚楚。仓库,东西要放在规整的货架上,甚至还会给货架编号。这里的数据很规范,用起来没那么灵活。
数据仓库就像是图书馆,里面的数据按照规范放好,你可以按照类别找到想要的信息。

数据仓库的规范性有利于数据的长期、大量存放。即使你到一个新的图书馆,只要按照图书分类法索引,你就能找到想看的书籍。
1.3 湖还是仓?
曾经有一段时间,大家对于大数据的存储形式分裂为了两派。不断询问是选择数据湖,还是选择数据仓库?
选择数据湖,才能拥有数据的多样与灵活,有利于将不同的数据组合在一起,发现新的规律。
选择数据仓库,才能拥有数据的规范与清晰,有利于数据的便捷使用,也利于数据的长时间存储。
2 湖仓一体下的开发
小孩子才做选择题,大人全都要。
最好的形式就是前期在数据湖中进行开发、创造,然后等一切成熟之后,将整理后的数据在数据仓库中存储。
这就带来了一个搬运问题,需要不断把数据湖中的东西搬运到数据仓库。而且,同一份数据可能在数据湖和数据仓库中均有存储。而后期可能会导致数据的不一致。
看来全都要是有代价的!
这就是这个回答最开始说的搬运问题。
那么大的数据,搬起来又冗余,有浪费时间。冗余,浪费的是公司的存储空间,是钱;时间,浪费的是程序员的青春,是钱,更是生命啊!
所以,小孩子不是不想全都要,是真没那个条件。
现在阿里的湖仓一体创造了条件。
湖仓一体,即打通数据仓库和数据湖两套体系,让数据和计算在湖和仓之间自由流动,从而构建一个完整的有机的大数据技术生态体系。这就像是在你的面前放了一个摆满了文档的书桌(数据湖),也放了一个小书架(数据仓库)。于是两者的数据都可以随意获取,在灵活与规范之间取得了平衡!
3 湖仓一体下的公司
刚才说的是我等程序员的开发过程。上升到程序员的集合体——公司,也是一样的。
公司开发大数据产品时,不可能一上来就定义好数据的字段,然后上数据仓库。所以前期肯定要在数据湖中开发,这时,数据量也不大,数据湖成本低且灵活,十分适合。
然是,随着公司的发展,数据湖中的数据就显得杂乱了起来。长此以往,没有人能知道其中数据的具体含义!
于是,得上数据仓库。只有规范数据,才能让数据长久地发挥价值。
可见,对于公司而言:数据湖灵活易上手,对于公司初期发展是好的;数据仓库规范有未来,对于公司的长久发展是好的。
这个时候,就得进行数据的迁移。从数据湖迁移到数据仓库。
哎?
怎么又是迁移?
所以,湖仓一体的好处就体现出来了。
4 总结
所以:数据湖的灵活对于大数据前期开发和公司的前期部署是友好的;数据仓库的规范对于大数据后期运行和公司长期发展是友好的。两者不存在二选一的问题,结合使用是趋势。
而湖仓一体创造了两者结合使用的桥梁,对开发者和公司而言,都比较有意义。
码农福音,公司利器。
条件:
- 小孩子才做选择题,大人全都要。
- 用了湖仓一体就能全都要了。
结论:
- 用了湖仓一体就从小孩变成了大人。
所以?湖仓一体是生长激素!
回答完毕!
累死我了,有收获就点赞。
也欢迎关注我,我是高级软件架构师易哥。
偶尔出没解答软件架构和编程相关的问题。
可以访问个人知乎阅读更多文章:易哥(https://www.zhihu.com/people/yeecode),欢迎关注。
作者书籍推荐


